
YOLOv11: Überblick und Fortschritte
Bei der YOLO Vision 2024-Veranstaltung kündigte Ultralytics ein neues Mitglied der YOLO-Serie namens YOLOv11 an. Dieser Artikel bietet einen Überblick über das neue Modell, Anweisungen zur Durchführung von Inferenz mit YOLOv11 sowie die wichtigsten Fortschritte und Highlights des Modells im Vergleich zu seinem Vorgänger.
Einleitung
Das YOLOv11-Modell wurde entwickelt, um schnell, genau und benutzerfreundlich zu sein und Aufgaben wie Objekterkennung, Bildsegmentierung, Bildklassifizierung, Pose-Schätzung und Echtzeit-Objektverfolgung zu unterstützen. Das neue State-of-the-Art (SOTA)-Modell hat eine schnellere Inferenzgeschwindigkeit und eine verbesserte Genauigkeit im Vergleich zu den vorherigen YOLO-Modellen erreicht. Bevor wir beginnen, werfen wir einen Blick auf die von Ultralytics bereitgestellten Benchmark-Ergebnisse.
Benchmark-Ergebnisse
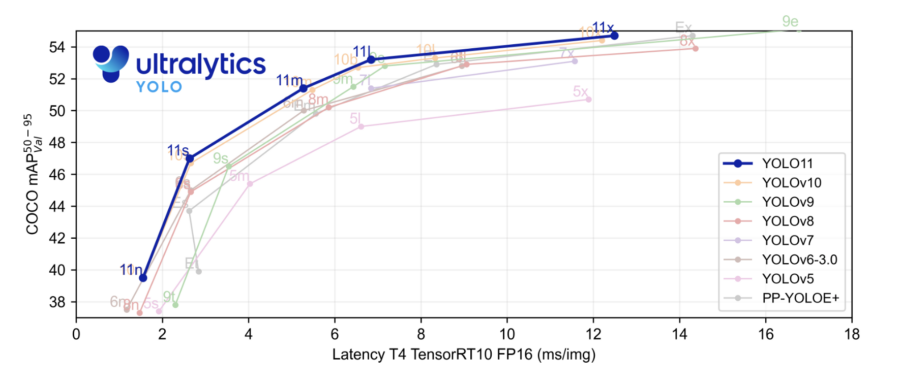
In der Benchmark-Plot-Darstellung wurde das YOLOv11-Modell mit YOLOv5, v6, v7, v8, v9 und v10 verglichen. Die hervorgehobene blaue Linie zeigt die Leistung von YOLOv11, und wie wir sehen können, hat es nahezu alle YOLO-Modelle oder -Serien in Bezug auf die mittlere durchschnittliche Präzision auf dem COCO-Datensatz und die Inferenzgeschwindigkeit auf der x-Achse übertroffen.
Von YOLOv11 unterstützte Aufgaben
- Objekterkennung: Lokalisierung von Objekten in einem Bild oder Video durch Zeichnen von Begrenzungsrahmen zusammen mit den Konfidenzbewertungen. Nützlich für Anwendungen wie autonomes Fahren, Überwachungskameras oder Mautstellen.
- Instanzsegmentierung: Identifizierung und Segmentierung von Objekten oder Individuen in einem Bild. Nützlich für medizinische Bildgebung, Fertigung und mehr.
- Pose-Schätzung: Identifizierung von Schlüsselpunkten in einem Bild oder Videoframe zur Überwachung von Körperbewegungen oder Gesten, nützlich für Anwendungen wie virtuelle Realität, Tanztraining und Physiotherapie.
- Orientierte Objekterkennung (OBB): Erkennung von Objekten mit einem Orientierungswinkel, der eine genauere Lokalisierung von gekippten oder gedrehten Objekten ermöglicht. Besonders nützlich für Anwendungen wie autonomes Fahren, industrielle Inspektionen und die Analyse von Bildern von Drohnen oder Satelliten.
Modellversionen
| Modell | Aufgaben |
|---|---|
| YOLO11 | Erkennung (COCO) |
| YOLO11-seg | Segmentierung (COCO) |
| YOLO11-pose | Pose/Schlüsselpunkte (COCO) |
| YOLO11-obb | Orientierte Erkennung (DOTAv1) |
| YOLO11-cls | Klassifizierung (ImageNet) |
YOLOv11 bietet Detect-, Segment- und Pose-Modelle, die auf dem COCO-Datensatz vortrainiert sind, sowie Classify-Modelle, die auf dem ImageNet-Datensatz vortrainiert sind. Der Track-Modus ist auch für alle Detect-, Segment- und Pose-Modelle verfügbar. Weitere Informationen zu den Modelldetails und seinen verschiedenen Versionen finden Sie im offiziellen GitHub-Repository. Wir haben für Sie einen direkten Link in unserem Ressourcenbereich aufgenommen.
 Voraussetzungen
Voraussetzungen
 Voraussetzungen
VoraussetzungenHier sind die Voraussetzungen für die Verwendung von YOLO-Modellen:
- Python-Umgebung: Installieren Sie Python 3.8 oder höher.
- CUDA & cuDNN: Eine CUDA-kompatible GPU (NVIDIA) mit installiertem CUDA und cuDNN für schnelleres Training und Inferenz.
- PyTorch: Installieren Sie PyTorch, das mit Ihrer CUDA-Version kompatibel ist.
- YOLO-Framework: Installieren Sie das spezifische YOLO-Versionspaket von Ultralytics.
- Datensatz: Beschrifteter Datensatz im YOLO-Format (Bilder und Annotationsdateien).
- Hardwareanforderungen: Mindestens 16 GB RAM und eine GPU mit 4+ GB VRAM für reibungsloses Training und Inferenz.
Wichtige Funktionshighlights des neuen Modells
YOLOv11 bringt mehrere Verbesserungen mit sich, die es zu einer starken Wahl für Computer-Vision-Aufgaben machen. Es verfügt über ein verbessertes Backbone- und Neck-Design, wodurch Objekte genauer erkannt und komplexe Aufgaben leichter bewältigt werden. Das Modell ist auf Geschwindigkeit optimiert und bietet schnellere Verarbeitungszeiten bei gleichzeitig guter Balance zwischen Genauigkeit und Leistung. Trotz 22 % weniger Parametern als YOLOv8m erreicht dieses leichte Modell eine höhere Genauigkeit, was es sowohl effizient als auch leistungsfähig macht.
YOLOv11 bietet zudem eine 2 % schnellere Inferenzzeit als YOLOv10 und ist somit hochgradig anpassungsfähig. Es funktioniert auf verschiedenen Plattformen, darunter Edge-Geräte, Cloud-Systeme und NVIDIA-GPUs. Zudem unterstützt es eine breite Palette von Aufgaben, darunter Objekterkennung, Bildklassifikation, Pose-Estimation und mehr.
Nahtlose Integration in verschiedene Systeme
YOLOv11 wurde für eine einfache Integration in verschiedene Systeme und Plattformen entwickelt. Aufbauend auf der Unterstützung von YOLOv8 funktioniert es gut in unterschiedlichen Umgebungen für Training, Test und Einsatz. Egal, ob NVIDIA-GPUs, Edge-Geräte oder Cloud-Plattformen – YOLOv11 fügt sich nahtlos in bestehende Workflows ein. Diese Eigenschaften machen YOLOv11 besonders vielseitig für verschiedene Branchen.
YOLOv11-Demo
Wenn YOLOv11 auf einer ccloud³ VM mit Cloud GPU ausgeführt wird, erreicht die Inferenzgeschwindigkeit bis zu 5 bis 6 ms pro Bild. Damit eignet es sich ideal für Echtzeitanwendungen, die schnelle und effiziente Verarbeitung erfordern.
Installation des ultralytics-Pakets
!pip install ultralytics --upgrade
Training des YOLOv11-Modells für die Objekterkennung
Das Training kann sowohl in Python als auch über die CLI erfolgen.
from ultralytics import YOLO
# COCO-vortrainiertes YOLO11n-Modell laden
model = YOLO("yolo11n.pt")
# Trainiere das Modell mit dem COCO8-Datensatz für 100 Epochen
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# CLI-Version des Trainings
yolo train model=yolo11n.pt data=coco8.yaml epochs=100 imgsz=640
Objekterkennung in einem Video
Der folgende Code verwendet das Modell zur Erkennung von Objekten in einem Video.
# COCO-vortrainiertes YOLO11n-Modell laden
model = YOLO("yolo11n.pt")
results = model("data/video.mp4", save=True, show=True)
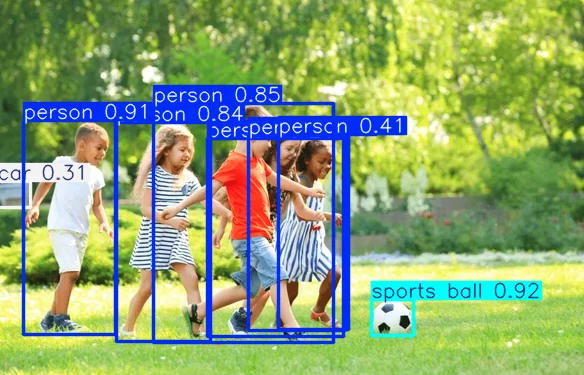
Objekterkennung in einem Bild
# COCO-vortrainiertes YOLO11n-Modell laden
model = YOLO("yolo11n.pt")
results = model("/folder_path/image_det.jpeg")
results[0].show()
Segmentierung mit YOLOv11
Für die Segmentierung muss YOLOv11 heruntergeladen werden, da das direkte Ausführen zu Fehlern führen kann.
# Segmentierung
from ultralytics import YOLO
model = YOLO('yolo11n-seg.pt')
results = model("/folder_path/image_seg.jpeg")
results[0].show()

Pose-Estimation mit YOLOv11
# Pose-Estimation
from ultralytics import YOLO
model = YOLO('yolo11n-pose.pt')
results = model("/folder_path/image_pose.jpeg")
results[0].show()

Bildklassifikation mit YOLOv11
# Bildklassifikation
from ultralytics import YOLO
model = YOLO('yolo11n-cls.pt')
results = model("/folder_path/image_class.jpeg")
results[0].show()

Empfohlene Hardware für YOLOv11
Es wird empfohlen, eine leistungsstarke GPU für das Training oder die Ausführung von YOLOv11 zu verwenden. Andernfalls könnte das Training oder die Inferenz langsam und ineffizient sein. GPUs sind speziell für parallele Berechnungen ausgelegt und können die komplexen Matrixoperationen, die für Deep Learning erforderlich sind, wesentlich schneller als CPUs ausführen. Daher kann die Wahl einer GPU für YOLOv11 die Leistung und Effizienz erheblich steigern.
Fazit
Wir haben einige beeindruckende Funktionen von YOLOv11 in Bezug auf Bilder und Videos gesehen. YOLOv11 ist ein leistungsstarkes und vielseitiges Modell für Computer-Vision-Aufgaben. Durch verbesserte Architektur, höhere Geschwindigkeit und Genauigkeit stellt es ein erhebliches Upgrade gegenüber seinen Vorgängern dar.
Zusammenfassend lässt sich sagen, dass YOLOv11 einen großen Fortschritt in der Objekterkennung und Computer Vision darstellt. Mit seinem besseren Design, schnelleren Berechnungen und gesteigerter Genauigkeit eignet es sich hervorragend für verschiedene Anwendungen – von Echtzeit-Erkennung auf kleinen Geräten bis hin zu detaillierten Analysen in der Cloud. Seine nahtlose Integration in bestehende Systeme macht es zu einer wertvollen Lösung für Unternehmen in Bereichen wie Landwirtschaft, Sicherheit und Robotik.
YOLOv11 bietet eine gelungene Kombination aus Flexibilität und Leistung und ist damit ein leistungsstarkes Werkzeug für alle, die sich mit Computer-Vision-Herausforderungen beschäftigen.
Dies ist der erste Teil des Tutorials. Im zweiten Teil werden wir lernen, wie man das Modell für die Objekterkennung auf einem individuellen Datensatz feintunen und trainieren kann.
