
Verständnis von Vektor-Datenbanken und ihrer Bedeutung
Die Einschränkungen traditioneller Datenbanken sind in einer Welt voller hochdimensionaler Daten kein Rätsel mehr. Vektor-Datenbanken sind Datenbanksysteme, die speziell für die Speicherung und Verwaltung hochdimensionaler Vektoren entwickelt wurden, die numerische Darstellungen von Daten enthalten und semantische Informationen erfassen.
Dieser Artikel stellt einige der beliebtesten Vektor-Datenbank-Tools vor, darunter Pinecone, FAISS, Weaviate, Milvus, Chroma, Elastic Vector Search, Annoy und Qdrant. Wir untersuchen ihre Stärken, Schwächen und Anwendungsfälle, um den Leser im wachsenden Bereich der Vektor-Datenbanken zu unterstützen.
Voraussetzungen
Um diesem Tutorial folgen zu können, sollten Sie ein Verständnis für hochdimensionale Daten, Vektor-Embeddings und Ähnlichkeitssuchen haben. Außerdem sind Grundkenntnisse in Python, Rust oder TypeScript sowie maschinelle Lerntechniken mit Frameworks wie PyTorch erforderlich. Sie müssen wissen, wie man eine Entwicklungsumgebung mit Python 3.8+ und maschinellen Lernbibliotheken einrichtet, um Pinecone, FAISS, Milvus und Qdrant effizient nutzen zu können.
Warum sind Vektor-Datenbanken notwendig?
Verständnis von hochdimensionalen Daten
Hochdimensionale Daten, die viele Variablen enthalten, sind in Anwendungen weit verbreitet, in denen komplexe Merkmale berechnet und verglichen werden müssen. Beispielsweise kann jedes Wort in der natürlichen Sprachverarbeitung (NLP) als Vektor kodiert werden, wobei ähnliche Wörter nahe beieinander liegen. Solche Vektorrepräsentationen erfassen Nuancen und ermöglichen die Analyse komplexer Beziehungen. Traditionelle Datenbanken tun sich schwer mit dieser Art von Daten, da sie auf tabellarische Datenstrukturen angewiesen sind. Vektor-Datenbanken hingegen sind speziell für die effiziente Verwaltung hochdimensionaler Daten ausgelegt.
Der Bedarf an effizienter Ähnlichkeitssuche
Eine der wichtigsten Funktionen von Vektor-Datenbanken ist die Fähigkeit, Ähnlichkeitssuchen durchzuführen. Eine Ähnlichkeitssuche identifiziert den “nächsten” Datensatz in der Datenbank zu einem gegebenen Vektor. Dies ist entscheidend für Anwendungen wie Empfehlungssysteme und Personalisierungstools. Im Gegensatz zu traditionellen Schlüsselwortsuchen oder SQL-Abfragen basieren Ähnlichkeitssuchen auf fortschrittlichen Indexierungsmechanismen wie Approximate Nearest Neighbors (ANN), die Vektor-Datenbanken unterstützen.
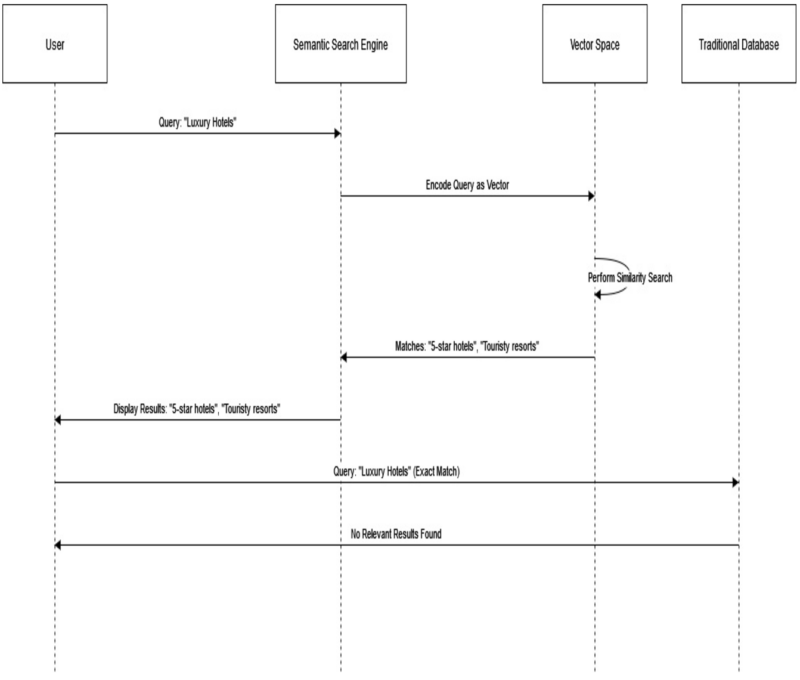
Zur Veranschaulichung betrachten wir eine semantische Suchmaschine. Wenn ein Benutzer nach “Luxushotels” sucht, interpretiert eine vektorbasierte Suchmaschine die Anfrage und findet semantisch ähnliche Begriffe wie “5-Sterne-Hotels” oder “touristische Resorts”. Dadurch werden relevantere Ergebnisse geliefert.
Traditionelle Datenbanken würden mit solchen Abfragen Schwierigkeiten haben, da sie hauptsächlich exakte Übereinstimmungen oder starre SQL-Modelle verwenden. Sie sind nicht flexibel genug, um die feinen Beziehungen in Vektorräumen zu verstehen und zu verarbeiten.
Integration von KI und maschinellem Lernen
Vektor-Datenbanken sind von Natur aus ideal für Anwendungen in den Bereichen Künstliche Intelligenz (KI) und Maschinelles Lernen (ML). KI-Modelle generieren häufig Vektoren, um die von ihnen verarbeiteten Daten darzustellen. Eine effiziente Speicherung, Abfrage und Indexierung dieser Vektoren in Echtzeit ist für die nahtlose Integration in Anwendungen unerlässlich.
Betrachten wir ein Bildverarbeitungssystem als Beispiel. Wenn ein Benutzer ein Bild eines Wahrzeichens hochlädt, verarbeitet das KI-Modell das Bild und erstellt ein Vektor-Embedding, das Konturen, Farben und Texturen beschreibt. Dieser Vektor wird dann in einer Vektor-Datenbank gespeichert.
Wenn der Benutzer später ein ähnliches Bild hochlädt, durchsucht das System die Datenbank nach den ähnlichsten Vektor-Embeddings und identifiziert das Wahrzeichen. Die Effizienz der Speicherung, des Zugriffs und der Indexierung von Vektoren ist entscheidend für Echtzeit-Erkennung und Ähnlichkeitsabgleiche.
Aktuelle Optionen im Bereich der Vektor-Datenbanken
Einführung in Pinecone
Pinecone ist eine leistungsstarke Vektor-Datenbank, die speziell für moderne KI- und ML-Projekte entwickelt wurde. Als vollständig verwalteter Dienst reduziert Pinecone die Zeit zum Speichern, Indexieren und Abfragen großer Mengen von Vektordaten. Dadurch ist Pinecone ideal für Echtzeit-Ähnlichkeitssuchen und groß angelegte Anwendungen. Seine Einfachheit und Leistung machen Pinecone zu einem der Vorreiter im Bereich der Vektor-Datenbanken.
Funktionsweise von Pinecone
Pinecone ermöglicht Entwicklern das Speichern, Indexieren und Abfragen hochdimensionaler Daten als Vektoren. Dies ist besonders nützlich für Empfehlungssysteme oder semantische Suchmaschinen, bei denen die Ähnlichkeit zwischen Produkten verstanden werden muss.
1.Schritt: Pinecone installieren und importieren
pip install pinecone-client
Die notwendigen Module für Python-Code müssen ebenfalls importiert werden:
from pinecone import Pinecone, ServerlessSpec
2.Schritt: Pinecone initialisieren
pc = Pinecone(api_key="API_KEY")
3.Schritt: Einen Index erstellen
index_name = "index_use_case"
pc.create_index(name=index_name,
dimension=6,
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
4.Schritt: Mit dem Index verbinden
index = pc.Index("index_use_case")
5.Schritt: Daten in den Index einfügen
data = [
{"id": "items1", "values": [1, 2, 3, 4, 5, 6]},
{"id": "items2", "values": [8, 7, 6, 5, 4, 3]},
]
index.upsert(items=data)
6.Schritt: Den Index abfragen
query_v = [2, 1, 4, 3, 6, 5]
res = index.query(vector=query_v, top_k=3)
7.Schritt: Index verwalten
Listen aller Indizes abrufen:
print(pc.list_indexes())
Index löschen:
pc.delete_index("index_use_case")
Stärken von Pinecone
- Einfache Nutzung: Pinecone ist vollständig verwaltet, was die Implementierung erleichtert. Dank API-First-Struktur auch für Anfänger geeignet.
- Hohe Leistung: Selbst komplexe Ähnlichkeitssuchen werden in Millisekunden ausgeführt.
- Zuverlässige Skalierbarkeit: Wächst mit den Daten, ohne die Leistung zu beeinträchtigen.
- Cross-Plattform-Integration: Unterstützt nahtlose Integration mit verschiedenen KI-Frameworks.
Schwächen von Pinecone
- Begrenzte Flexibilität: Pinecones verwaltete Architektur erlaubt keine umfassende Anpassung wie bei selbst gehosteten Lösungen.
- Abhängigkeit von der Cloud: Für Unternehmen mit hohem Bedarf an On-Premise-Daten möglicherweise ungeeignet.
FAISS erklärt: Optimierung der Ähnlichkeitssuche und des Clusterings für große Datenmengen
FAISS steht für Facebook AI Similarity Search. Es handelt sich um eine Open-Source-Bibliothek, die für die Ähnlichkeitssuche und das Clustering dichter Vektoren entwickelt wurde. Dichte Vektoren sind numerische Darstellungen von Daten (z.B. Text-Embeddings, Bilder, Audio) in maschinellen Lernmodellen.
FAISS ist optimiert, um:
- die nächstgelegenen Nachbarn eines Abfragevektors unter Millionen oder Milliarden anderer Vektoren zu finden,
- schnelle und speichereffiziente Leistung durch Produktquantisierung und invertierte Dateiindexierung zu bieten,
- sowohl auf CPUs als auch GPUs zu skalieren und Echtzeit- sowie großflächige Offline-Bereitstellungen zu ermöglichen.
Wie FAISS funktioniert
Indexierung
FAISS erstellt einen Vektorindex mit verschiedenen Techniken zur Optimierung von Ähnlichkeitssuchen:
- Flat Index: Organisiert Vektoren für eine vollständige Suche. Hohe Genauigkeit, aber rechenintensiv bei großen Datensätzen.
- IVF (Invertierte Datei): Partitioniert Vektoren in Cluster und beschränkt die Suche auf relevante Cluster.
- Produktquantisierung (PQ): Reduziert Vektoren zu kleineren Darstellungen, tauscht etwas Genauigkeit gegen schnellere Suche und geringeren Speicherbedarf.
- HNSW (Hierarchical Navigable Small World): Erzeugt einen Graphen, in dem Knoten Vektoren repräsentieren, was schnelle Navigation zu Nachbarn ermöglicht.
Suchanfragen
FAISS durchsucht indizierte Vektoren mit exakten oder ungefähren Methoden:
- Exakte Suche: Der Abfragevektor wird mit allen Vektoren im Index verglichen.
- Ungefähre Suche: FAISS nutzt komprimierte Darstellungen oder Clustering-Techniken für schnellere Suchen bei geringem Genauigkeitsverlust.
Abstandsmetriken
FAISS bietet verschiedene Ähnlichkeitsmetriken:
- Euklidische Distanz: Misst die direkte Entfernung zwischen Vektoren.
- Kosinussimilarität: Misst den Winkel zwischen Vektoren zur Bestimmung ihrer Ähnlichkeit.
Erste Schritte mit FAISS
Installation
FAISS kann mit folgendem Befehl installiert werden:
pip install faiss-cpu
Für GPU-Unterstützung:
pip install faiss-gpu
Grundlegendes Anwendungsbeispiel
Hier ist ein einfaches Beispiel für die Implementierung von FAISS zur nächsten Nachbarsuche:
import numpy as np
import faiss
dim = 64 # Dimension der Vektoren
b = 10000 # Anzahl der Datenbankvektoren
q = 1000 # Anzahl der Abfragevektoren
np.random.seed(234)
x_b = np.random.random((b, dim)).astype('float32') # Datenbankvektoren
x_q = np.random.random((q, dim)).astype('float32') # Abfragevektoren
index = faiss.IndexFlatL2(dim) # L2-Distanzindex
index.add(x_b) # Hinzufügen der Datenbankvektoren
k = 3 # Anzahl der nächsten Nachbarn
D, I = index.search(x_q, k) # Suche nach den nächsten Nachbarn
print(I[:3]) # Ausgabe der Top-3-Ergebnisse
Stärken von FAISS
- Hohe Geschwindigkeit: FAISS ermöglicht extrem schnelle Ähnlichkeitssuchen, selbst bei Milliarden von Vektoren. GPU-Unterstützung erhöht die Leistung.
- Skalierbarkeit: Effiziente Skalierung für große Datensätze.
- Flexibilität: Verschiedene Indexierungsoptionen für individuelle Anforderungen.
- Open Source: Kostenlos und von einer aktiven Community unterstützt.
Schwächen von FAISS
- Komplexe Implementierung: Erfordert ein gutes Verständnis der Indexierungsverfahren.
- Genauigkeits- vs. Geschwindigkeitskompromiss: Ungefähre Suchen können an Genauigkeit verlieren.
- Hoher Speicherverbrauch: Exakte Suchen erfordern viel Speicher bei großen Datenmengen.
- Steile Lernkurve: Die Implementierung kann zeitaufwendig sein.
Weaviate: Eine Open-Source Vektor-Datenbank
Weaviate ist eine fortschrittliche Open-Source-Datenbank zur Speicherung von Rohdaten und deren semantischen Repräsentationen. Im Gegensatz zu traditionellen SQL-Datenbanken verwendet Weaviate KI-gesteuerte Vektor-Embeddings für kontextbasierte Suchanfragen. Diese Funktionalität ist besonders relevant für Anwendungen wie Conversational AI, Empfehlungssysteme und Inhaltskategorisierung.
Wie Weaviate semantisches Verständnis ermöglicht
Weaviate transformiert eine Suchanfrage, z.B. „Biologie“, in eine semantische Vektorrepräsentation und vergleicht diese mit gespeicherten Vektoren, um kontextuell passende Ergebnisse zu liefern. Dadurch erhält der Nutzer relevante Ergebnisse, auch wenn diese nicht exakt das gesuchte Stichwort enthalten.
Der Prozess funktioniert wie folgt:
- Suchanfrage: Ein Benutzer gibt den Begriff „Biologie“ ein. Traditionelle Datenbanken führen eine einfache Stichwortsuche durch.
- Umwandlung in einen Vektor: Weaviate wandelt die Anfrage mithilfe von Modellen wie OpenAI oder Sentence Transformers in einen Vektor um, der die semantische Bedeutung erfasst.
- Vergleich ähnlicher Vektoren: Der Vektor wird mit gespeicherten Datenvektoren verglichen, z.B. mittels Kosinus-Ähnlichkeit.
- Bereitstellung relevanter Ergebnisse: Weaviate liefert Ergebnisse, die auf semantischen Ähnlichkeiten basieren, nicht nur auf exakten Stichwörtern.
Stärken von Weaviate
- Semantische Suche: Weaviate versteht die Bedeutung von Suchanfragen und liefert relevantere Ergebnisse als klassische Suchmaschinen.
- Modulare Vektorisierung: Unterstützt verschiedene Vektorisierungsmodelle (OpenAI, Hugging Face).
- Hohe Performance: Nutzt HNSW-Indexierung für schnelle Abfragen, selbst bei Millionen von Datensätzen.
- Benutzerfreundliche APIs: GraphQL und REST APIs erleichtern die Integration in bestehende Systeme.
Schwächen von Weaviate
- Modellabhängigkeit: Die Genauigkeit der Ergebnisse hängt stark vom verwendeten Vektorisierungsmodell ab.
- Hoher Rechenaufwand: Die Umwandlung von Daten in Vektoren und deren Speicherung erfordern erhebliche Rechenressourcen.
- Komplexe Einrichtung: Die Konfiguration kann für Einsteiger in Vektor-Datenbanken anspruchsvoll sein.
- Limitierungen bei traditionellen Abfragen: SQL-ähnliche Operationen werden weniger effizient unterstützt.
Milvus: Einrichtung von Milvus Lite für lokale Vektor-Datenbankverwaltung
Milvus ist eine Open-Source-Vektor-Datenbank, die für die effiziente Organisation und Suche von Vektordaten in großem Maßstab entwickelt wurde. Sie ist besonders nützlich für Wissensdatenbanken, semantische Suche und Retrieval-Augmented Generation (RAG)-Anwendungen.
Installation von Milvus Lite
pip install -U pymilvus
Erstellen einer Collection in Milvus
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection",
dimension=768,
)
Einfügen von Daten in Milvus
from pymilvus import model
embedding_fn = model.DefaultEmbeddingFunction()
documents = [
"Künstliche Intelligenz ist ein Bereich der Informatik.",
"Heute gibt es viele Informatiker.",
"Deep Learning ist ein Teilbereich der Künstlichen Intelligenz."
]
vectors = embedding_fn.encode_documents(documents)
dataset = [
{"id": i, "vector": vectors[i], "text": documents[i], "subject": "Informatik"}
for i in range(len(vectors))
]
res = client.insert(collection_name="demo_collection", data=dataset)
print(res)
Abfragen der Milvus-Datenbank
query_vectors = embedding_fn.encode_queries(["Was ist Deep Learning?"])
res = client.search(
collection_name="demo_collection",
data=query_vectors,
limit=2,
output_fields=["text", "subject"]
)
print(res)
Stärken von Milvus
- Hohe Leistung: Optimiert für schnelle Ähnlichkeitssuchen bei großen Datensätzen.
- Skalierbarkeit: Unterstützt große Datenmengen ohne Leistungseinbußen.
- Aktive Community: Umfangreiche Dokumentation und starker Support.
Schwächen von Milvus
- Komplexe Einrichtung: Erfordert technisches Know-how für Implementierung und Skalierung.
- Hoher Ressourcenbedarf: Benötigt erhebliche Infrastrukturressourcen für den großflächigen Einsatz.
Chroma Vektor-Datenbank
Chroma ist eine leichtgewichtige und benutzerfreundliche Vektor-Datenbank, die für schnelle Implementierung und einfache Nutzung entwickelt wurde. Sie ist besonders geeignet für kleine Anwendungen und Prototyp-Projekte, bei denen Einfachheit und schnelle Integration im Vordergrund stehen.
Stärken von Chroma
- Einfache Einrichtung: Chroma lässt sich schnell installieren und konfigurieren, ohne dass tiefgehende technische Kenntnisse erforderlich sind.
- Leichtgewichtiges Design: Ideal für Umgebungen mit begrenzten Ressourcen.
- Echtzeit-Aktualisierungen: Unterstützt dynamische Datenerfassung und sofortige Aktualisierung von Embeddings.
- API-Integration: Bietet eine benutzerfreundliche API zur nahtlosen Integration mit verschiedenen Programmiersprachen und Machine-Learning-Frameworks.
Schwächen von Chroma
- Begrenzte Skalierbarkeit: Chroma stößt bei der Verarbeitung großer Datensätze schnell an seine Grenzen.
- Fehlende erweiterte Funktionen: Bietet nicht die umfassenden Features, die in größeren oder komplexeren Vektor-Datenbanken verfügbar sind.
Elastic Vector Search: Stärken, Schwächen und Anwendungsfälle
Elastic Vector Search erweitert die Funktionalität von Elasticsearch, um Ähnlichkeitssuchen über große Vektordatenmengen zu ermöglichen. Dies ist besonders nützlich für Empfehlungssysteme, Personalisierungstools und hybride Suchlösungen.
Stärken von Elastic Vector Search
- Skalierbarkeit: Unterstützt horizontale Skalierung und verteilte Architekturen für große Datensätze.
- Hybride Suche: Ermöglicht die Kombination von Keyword- und Vektorsuchen für flexible und präzisere Abfragen.
- Integration mit Elastic Stack: Nahtlose Integration mit Tools wie Kibana für Visualisierung und Logstash für Datenverarbeitung.
- Anpassbare Schemata: Flexible Indexierungsmethoden, einschließlich HNSW, für optimale Leistung.
Schwächen von Elastic Vector Search
- Hoher Ressourcenverbrauch: Benötigt erhebliche Speicher- und CPU-Ressourcen, insbesondere bei großen Datensätzen.
- Komplexe Konfiguration: Die Einrichtung und Optimierung erfordert tiefgreifende Kenntnisse in Elasticsearch.
- Genauigkeitskompromisse: Ungefähre Näherungssuchen können zu Einbußen bei der Genauigkeit führen.
Annoy (Approximate Nearest Neighbors Oh Yeah)
Annoy ist eine Open-Source-Bibliothek, die von Spotify entwickelt wurde. Sie ist für schnelle, ungefähre Nächste-Nachbarn-Suchen in hochdimensionalen Räumen optimiert. Annoy eignet sich ideal für Anwendungsfälle wie Empfehlungssysteme und Suchmaschinen, bei denen schnelle, aber nicht unbedingt exakte Ergebnisse gefragt sind.
Stärken von Annoy
- Schnelle Näherungssuche: Verwendet baumbasierte Indexierung für effiziente Suchabfragen.
- Speichereffizienz: Nutzt speichergemappte Dateien, um große Datensätze ohne vollständiges Laden in den Arbeitsspeicher zu verwalten.
- Einfache API: Bietet eine benutzerfreundliche API für einfache Integration in Anwendungen.
Schwächen von Annoy
- Einzel-Thread-Indexierung: Der Indexaufbau erfolgt nur auf einem Thread, was bei großen Datenmengen zu Verzögerungen führen kann.
- Abstriche bei der Genauigkeit: Die Optimierung auf Geschwindigkeit geht zulasten der Genauigkeit.
- Begrenzte Datenbank-Funktionalitäten: Fokus ausschließlich auf Vektorsuche ohne zusätzliche Datenbankfeatures.
Qdrant: Open-Source Vektor-Datenbank für schnelle und präzise Ähnlichkeitssuche
Qdrant ist eine Open-Source-Vektor-Datenbank, die für schnelle Ähnlichkeitssuchen und die effiziente Verarbeitung hochdimensionaler Daten entwickelt wurde. Sie eignet sich besonders für Machine-Learning- und KI-Anwendungen.
 Qdrant Architektur
Qdrant Architektur
 Qdrant Architektur
Qdrant ArchitekturQdrant organisiert Daten in Collections, die logisch zusammengehörige Datensätze bündeln. Jede Collection besteht aus:
- Vektoren: Hochdimensionale Datenrepräsentationen.
- Payloads: Metadaten, die zusätzlichen Kontext oder Eigenschaften für jeden Vektor bereitstellen.
Ähnlichkeitssuche in Qdrant
Qdrant verwendet erweiterte Distanzmetriken für Ähnlichkeitssuchen:
- Euklidische Distanz: Misst die direkte Entfernung zwischen Vektoren.
- Kosinussimilarität: Vergleicht Vektoren anhand des Winkels zwischen ihnen.
- Skalarprodukt: Misst die Projektion eines Vektors auf einen anderen.
Stärken von Qdrant
- Hohe Leistung: Schnelle und präzise Suchen dank HNSW-Indexierung.
- Echtzeit-Aktualisierungen: Unterstützt dynamische Dateneingaben für Echtzeitanwendungen.
- Flexible Abfragen: Bietet Filterung und Metadatenmanagement für komplexe Anfragen.
Schwächen von Qdrant
- Komplexe Einrichtung: Erfordert technisches Fachwissen für Implementierung und Optimierung.
- Hohe Infrastrukturkosten: Große Deployments erfordern umfangreiche Infrastrukturressourcen.
Fazit
Vektor-Datenbanken haben die Verwaltung hochdimensionaler Daten revolutioniert, indem sie die Einschränkungen traditioneller Datenbanken überwinden. Sie ermöglichen moderne Anwendungen wie Empfehlungssysteme, semantische Suche und KI-gesteuerte Lösungen.
Ob Pinecone, FAISS, Weaviate, Milvus, Chroma, Elastic Vector Search, Annoy oder Qdrant – jede dieser Datenbanken bietet einzigartige Vorteile für spezifische Anwendungsfälle. Ihre Limitierungen wie Kosten, Komplexität oder Kompromisse zwischen Geschwindigkeit und Genauigkeit müssen jedoch sorgfältig abgewogen werden.
Die Wahl der passenden Vektor-Datenbank hängt von den spezifischen Anwendungsanforderungen, der vorhandenen Infrastruktur und den verfügbaren Ressourcen ab. Eine wohlüberlegte Entscheidung garantiert optimale Integration und hohe Leistung.
