
Tiefes Lernen für Bildsegmentierung: U-Net und CANet
Die Anwendungen von Deep-Learning-Modellen und Computer Vision nehmen in der modernen Ära rasant zu. Computer Vision ist ein Bereich der künstlichen Intelligenz, in dem wir unsere Modelle darauf trainieren, reale visuelle Bilder zu interpretieren. Mit Hilfe von Deep-Learning-Architekturen wie U-Net und CANet können wir qualitativ hochwertige Ergebnisse auf Computer-Vision-Datensätzen erzielen, um komplexe Aufgaben zu bewältigen. Während Computer Vision ein riesiges Feld mit vielen Möglichkeiten und einzigartigen Problemstellungen ist, konzentrieren wir uns in den nächsten Artikeln auf zwei Architekturen – U-Net und CANet –, die speziell für die Bildsegmentierung entwickelt wurden.
Verständnis der Bildsegmentierung
Die Aufgabe der Bildsegmentierung besteht darin, ein Bild in mehrere kleinere Fragmente zu unterteilen. Diese Segmente helfen bei der Berechnung von Bildsegmentierungsaufgaben. Eine weitere wesentliche Voraussetzung für Bildsegmentierungsaufgaben ist die Verwendung von Masken. Mithilfe von Maskierung, also einem binären Bild mit null oder nicht-null Werten, können wir das gewünschte Ergebnis für die Segmentierungsaufgabe erhalten. Sobald wir die wichtigsten Bestandteile des Bildes mit Hilfe von Bildern und ihren jeweiligen Masken beschrieben haben, können wir eine Vielzahl zukünftiger Aufgaben damit bewältigen.
Anwendungen der Bildsegmentierung
Einige der wichtigsten Anwendungen der Bildsegmentierung umfassen Maschinenvision, Objekterkennung, medizinische Bildsegmentierung, Gesichtserkennung und vieles mehr.
Voraussetzungen
- Python: Grundlegendes Verständnis der Python-Programmierung.
- Deep Learning: Vertrautheit mit neuronalen Netzwerken, insbesondere CNNs und Objekterkennung.
- PyTorch oder TensorFlow: Kenntnisse in einer dieser Frameworks sind erforderlich, um dem Artikel zu folgen.
Einführung in U-Net
Die U-Net-Architektur, die erstmals im Jahr 2015 veröffentlicht wurde, hat die Welt des Deep Learning revolutioniert. Die Architektur gewann die International Symposium on Biomedical Imaging (ISBI) Cell Tracking Challenge 2015 in zahlreichen Kategorien mit großem Vorsprung. Einige ihrer bedeutendsten Anwendungen umfassen die Segmentierung neuronaler Strukturen in elektronenmikroskopischen Aufnahmen und Bildern aus der Transmissionslichtmikroskopie.
Mit dieser U-Net-Architektur kann die Segmentierung von Bildern mit einer Größe von 512×512 mit einer modernen GPU innerhalb kurzer Zeit berechnet werden. Aufgrund ihres außergewöhnlichen Erfolgs gibt es zahlreiche Varianten und Modifikationen dieser Architektur. Einige davon sind LadderNet, U-Net mit Attention-Mechanismen, das rekurrente und residuale Faltungs-U-Net (R2-UNet) sowie U-Net mit ResNet-Blöcken oder dicht verbundenen Blöcken.
Frühere Methoden der Bildsegmentierung
Obwohl U-Net ein bedeutender Meilenstein im Bereich des Deep Learning ist, ist es ebenso wichtig, die vorherigen Methoden zu verstehen, die zur Lösung ähnlicher Aufgaben eingesetzt wurden. Ein herausragendes Beispiel ist der Sliding-Window-Ansatz, der 2012 die EM-Segmentierungs-Challenge beim ISBI mit großem Abstand gewann. Der Sliding-Window-Ansatz ermöglichte die Generierung einer Vielzahl von Beispiel-Patches zusätzlich zu den ursprünglichen Trainingsdaten.
Dieser Ansatz funktionierte, indem er ein Netzwerk aufbaute, bei dem jedes Pixel als separate Einheit betrachtet wurde. Dabei wurde ein lokaler Bereich (Patch) um das jeweilige Pixel herum genutzt. Eine weitere Stärke dieser Architektur war die Fähigkeit, sich leicht an jedes beliebige Trainingsset für spezifische Aufgaben anzupassen.
Herausforderungen des Sliding-Window-Ansatzes
Der Sliding-Window-Ansatz hatte jedoch zwei wesentliche Nachteile, die durch die U-Net-Architektur behoben wurden. Da jedes Pixel separat betrachtet wurde, führten die resultierenden Patches zu einer erheblichen Überlappung. Dadurch entstand eine große Redundanz. Ein weiterer Nachteil bestand darin, dass der gesamte Trainingsprozess sehr langsam war und viele Rechenressourcen verbrauchte. Aufgrund dieser Einschränkungen war die Praktikabilität dieser Netzwerkarchitektur fraglich.
Wie U-Net diese Herausforderungen löst
Die U-Net-Architektur ist eine elegante Lösung, die viele dieser Probleme behebt. Sie basiert auf dem Konzept vollfaltungsbasierter Netzwerke (Fully Convolutional Networks). Das Ziel von U-Net ist es, sowohl kontextuelle Merkmale als auch Lokalisierungsinformationen zu erfassen. Dies gelingt durch eine Architektur mit sukzessiven kontrahierenden Schichten, die direkt von Upsampling-Operatoren gefolgt werden, um hochauflösende Segmentierungsergebnisse auf Eingabebildern zu erzielen.
Die U-Net-Architektur verstehen
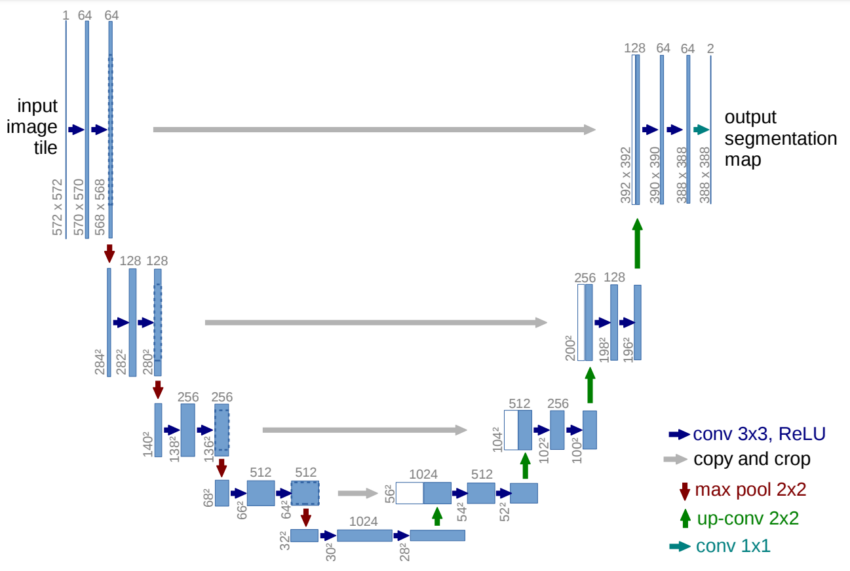
Wenn wir einen kurzen Blick auf die Architektur in der Abbildung werfen, erkennen wir sofort, warum sie als U-Net-Architektur bezeichnet wird. Die geformte Struktur ähnelt dem Buchstaben „U“, was ihr den Namen gibt. Allein durch das Betrachten der Struktur und der zahlreichen Elemente, die bei der Konstruktion dieser Architektur eine Rolle spielen, wird deutlich, dass es sich um ein vollständig faltungsbasiertes Netzwerk (Fully Convolutional Network) handelt. Es wurden keine anderen Schichten wie Dense-, Flatten- oder ähnliche Schichten verwendet. Die visuelle Darstellung zeigt einen anfänglichen kontrahierenden Pfad, gefolgt von einem expandierenden Pfad.
Wichtige Merkmale der U-Net-Architektur
Die Architektur zeigt, dass ein Eingabebild durch das Modell geleitet wird und dann durch mehrere Faltungsschichten mit der ReLU-Aktivierungsfunktion verarbeitet wird. Dabei reduziert sich die Bildgröße von 572×572 auf 570×570 und schließlich auf 568×568. Diese Reduktion entsteht durch die Verwendung von ungepolsterten Faltungen (definiert als „valid“), wodurch die Gesamtdimensionalität verringert wird. Neben den Faltungsblöcken sehen wir auch, dass auf der linken Seite ein Encoder-Block und auf der rechten Seite ein Decoder-Block vorhanden sind.
Struktur von Encoder und Decoder
Der Encoder-Block verkleinert die Bildgröße kontinuierlich mit Hilfe von Max-Pooling-Schichten mit einer Schrittweite von 2. Zudem werden wiederholt Faltungsschichten mit einer steigenden Anzahl an Filtern im Encoder-Bereich verwendet. Sobald wir den Decoder-Bereich erreichen, nimmt die Anzahl der Filter in den Faltungsschichten schrittweise ab, während die nachfolgenden Schichten kontinuierlich ein Upsampling durchführen – bis hin zur ursprünglichen Auflösung. Ein weiteres wichtiges Merkmal sind die Skip-Verbindungen, die frühere Ausgaben mit den Schichten in den Decoder-Blöcken verbinden.
Die Rolle der Skip-Verbindungen
Skip-Verbindungen sind ein entscheidendes Konzept, um den Verlust von Informationen aus den vorherigen Schichten zu bewahren, sodass sie sich stärker auf die Gesamtwerte auswirken. Wissenschaftliche Untersuchungen haben gezeigt, dass sie bessere Ergebnisse liefern und zu einer schnelleren Modellkonvergenz führen. Im letzten Faltungsblock gibt es mehrere Faltungsschichten, gefolgt von der endgültigen Faltungsschicht. Diese Schicht verfügt über einen Filter von 2 mit einer entsprechenden Funktion, um die endgültige Ausgabe anzuzeigen. Diese letzte Schicht kann je nach gewünschtem Anwendungszweck des Projekts angepasst werden.
TensorFlow-Implementierung von U-Net
In diesem Abschnitt des Artikels betrachten wir die Implementierung der U-Net-Architektur mit TensorFlow. Während ich TensorFlow für die Berechnungen des Modells verwende, kannst du auch ein anderes Deep-Learning-Framework wie PyTorch für eine ähnliche Implementierung nutzen. In zukünftigen Artikeln werden wir uns mit der Funktionsweise der U-Net-Architektur sowie mit weiteren Modellstrukturen in PyTorch befassen. Für diesen Artikel bleiben wir jedoch bei TensorFlow. Wir werden alle erforderlichen Bibliotheken importieren und unsere U-Net-Architektur von Grund auf neu aufbauen. Dabei werden wir einige notwendige Änderungen vornehmen, um die Gesamtleistung des Modells zu verbessern und es gleichzeitig etwas weniger komplex zu gestalten.
Modifikationen im implementierten Modell
Es ist wichtig zu beachten, dass das U-Net-Modell bereits im Jahr 2015 eingeführt wurde. Obwohl seine Leistung zu diesem Zeitpunkt hervorragend war, haben sich die wesentlichen Methoden und Funktionen des Deep Learning seither erheblich weiterentwickelt. Daher gibt es zahlreiche erfolgreiche Varianten und Versionen der U-Net-Architektur, die seit ihrer ursprünglichen Entwicklung entstanden sind. Diese Varianten dienen dazu, bestimmte Bildmerkmale zu erhalten, das ursprüngliche Modell nachzubilden und in manchen Fällen sogar bessere Ergebnisse als die ursprüngliche Architektur zu erzielen.
Ich werde versuchen, die meisten wesentlichen Parameter und architektonischen Elemente der ursprünglichen Implementierung der U-Net-Architektur beizubehalten. Allerdings wird es einige geringfügige Änderungen geben, die die moderne Effizienz verbessern und sowohl die Geschwindigkeit als auch die Einfachheit des Modells optimieren. Eine der Änderungen in dieser Struktur besteht darin, den Wert der Faltung als „same“ zu verwenden, da zahlreiche Untersuchungen in der Zukunft gezeigt haben, dass diese Änderung die Architektur in keiner Weise negativ beeinflusst. Außerdem wurde das Konzept der Batch-Normalisierung erst 2016 eingeführt, sodass es in der ursprünglichen Architektur nicht verwendet wurde. Unsere Modellimplementierung wird jedoch die Batch-Normalisierung einschließen, da sie in den meisten Fällen die besten Ergebnisse liefert.
Importieren der erforderlichen Bibliotheken
Für den Aufbau der U-Net-Architektur werden wir das TensorFlow-Deep-Learning-Framework verwenden, wie bereits besprochen. Daher importieren wir die TensorFlow-Bibliothek für diesen Zweck sowie das Keras-Framework, das nun ein integraler Bestandteil der TensorFlow-Modellstrukturen ist. Aus unserem bisherigen Verständnis der U-Net-Architektur wissen wir, dass einige der wesentlichen Importe die Faltungsschicht, die Max-Pooling-Schicht, eine Eingabeschicht und die Aktivierungsfunktion ReLU für die grundlegende Modellierung umfassen. Zusätzlich werden wir einige weitere Schichten wie die Conv2DTranspose-Schicht verwenden, die ein Upsampling für unsere gewünschten Decoder-Blöcke durchführt. Außerdem nutzen wir die Batch-Normalisierungsschichten zur Stabilisierung des Trainingsprozesses und die Concatenate-Schichten zum Kombinieren der erforderlichen Skip-Verbindungen.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, Activation, ReLU
from tensorflow.keras.layers import BatchNormalization, Conv2DTranspose, Concatenate
from tensorflow.keras.models import Model, Sequential
Erstellen des Faltungsblocks
Nachdem wir die erforderlichen Bibliotheken importiert haben, können wir mit dem Aufbau der U-Net-Architektur fortfahren. Dies kann entweder in einer vollständigen Klasse erfolgen, in der alle Parameter und Werte in der richtigen Reihenfolge definiert und der Prozess bis zum Ende durchgeführt wird, oder in mehreren iterativen Blöcken. Ich werde die zweite Methode verwenden, da sie für die meisten Nutzer einfacher ist, um die Architektur des U-Net-Modells besser zu verstehen. Wir werden drei iterative Blöcke verwenden, die in der Architektur-Darstellung gezeigt sind, nämlich den Faltungsoperationsblock, den Encoder-Block und den Decoder-Block. Mit diesen drei Blöcken können wir die U-Net-Architektur problemlos aufbauen. Lassen Sie uns nun die Funktionsblöcke einzeln durchgehen und verstehen.
Faltungsoperationsblock im Deep Learning
Der Faltungsoperationsblock dient dazu, die primäre Operation durchzuführen, indem die eingegebenen Parameter verarbeitet und eine doppelte Schicht von Faltungsoperationen angewendet wird. In dieser Funktion gibt es zwei Argumente: die Eingabe für die Faltungsschicht und die Anzahl der Filter, die standardmäßig auf 64 gesetzt ist. Wir verwenden den Wert „same“ für das Padding, wie zuvor besprochen, um die gleiche Form beizubehalten, anstatt ungepolsterte oder „valid“-Faltungen zu nutzen. Diese Faltungsschichten werden von einer Batch-Normalisierungsschicht gefolgt. Diese Änderungen gegenüber dem ursprünglichen Modell wurden vorgenommen, um die bestmöglichen Ergebnisse zu erzielen. Abschließend wird eine ReLU-Aktivierungsschicht hinzugefügt, wie in der Forschungsarbeit definiert. Lassen Sie uns den Codeblock zur Erstellung des Faltungsblocks erkunden.
Implementierung des Faltungsoperationscodes
def convolution_operation(entered_input, filters=64):
# Erste Eingabe nehmen und den ersten Faltungsblock implementieren
conv1 = Conv2D(filters, kernel_size=(3,3), padding="same")(entered_input)
batch_norm1 = BatchNormalization()(conv1)
act1 = ReLU()(batch_norm1)
# Erste Eingabe nehmen und den zweiten Faltungsblock implementieren
conv2 = Conv2D(filters, kernel_size=(3,3), padding="same")(act1)
batch_norm2 = BatchNormalization()(conv2)
act2 = ReLU()(batch_norm2)
return act2
Konstruktion der Encoder- und Decoder-Blöcke
Unser nächster Schritt besteht darin, die Encoder- und Decoder-Blöcke zu erstellen. Diese beiden Funktionen sind relativ einfach zu konstruieren. Die Encoder-Architektur verarbeitet aufeinanderfolgende Eingaben, beginnend mit der ersten Schicht bis hin zur tiefsten Ebene. Die von uns definierte Encoder-Funktion enthält den Faltungsblock, d. h. zwei Faltungsschichten, gefolgt von ihren jeweiligen Batch-Normalisierungs- und ReLU-Schichten. Sobald wir diese durch die Faltungsblöcke geleitet haben, werden wir diese Elemente gemäß der Forschungsarbeit schnell herunterskalieren. Wir werden eine Max-Pooling-Schicht verwenden und uns an die in der Arbeit erwähnten Parameter halten, wobei die Schritte = 2 betragen. Wir geben sowohl die ursprüngliche Ausgabe als auch die max-gepoolte Ausgabe zurück, da wir die erste für die Skip-Verbindungen benötigen.
Decoder-Block im Deep Learning
Der Decoder-Block enthält drei Argumente: die empfangenen Eingaben, die Eingabe der Skip-Verbindung und die Anzahl der Filter im jeweiligen Baustein. Wir werden die eingegebene Eingabe mit Hilfe der Conv2DTranspose-Schichten in unserem Modell hochskalieren. Anschließend werden wir sowohl die empfangene Eingabe als auch die neu hochskalierten Schichten zusammenführen, um den endgültigen Wert der Skip-Verbindungen zu erhalten. Danach verwenden wir diese kombinierte Funktion und führen unsere Faltungsblock-Operation durch, um zur nächsten Schicht überzugehen und diese Ausgabe zurückzugeben.
Implementierung des Encoder- und Decoder-Blocks
def encoder(entered_input, filters=64):
# Erfassung des Anfangs- und Endpunkts jedes Unterblocks für normalen Durchgang und Skip-Verbindungen
enc1 = convolution_operation(entered_input, filters)
MaxPool1 = MaxPooling2D(strides=(2,2))(enc1)
return enc1, MaxPool1
def decoder(entered_input, skip, filters=64):
# Hochskalieren und Zusammenführen der wesentlichen Merkmale
Upsample = Conv2DTranspose(filters, (2, 2), strides=2, padding="same")(entered_input)
Connect_Skip = Concatenate()([Upsample, skip])
out = convolution_operation(Connect_Skip, filters)
return out
Konstruktion der U-Net-Architektur
Wenn du die gesamte U-Net-Architektur von Grund auf in einer einzigen Schicht aufbauen möchtest, wirst du feststellen, dass die Gesamtstruktur sehr umfangreich ist, da sie aus vielen verschiedenen Blöcken besteht, die verarbeitet werden müssen. Indem wir unsere Funktionen in drei separate Code-Blöcke für die Faltungsoperation, die Encoder-Struktur und die Decoder-Struktur aufteilen, können wir die U-Net-Architektur mit nur wenigen Codezeilen effizient konstruieren. Wir werden die Eingabeschicht verwenden, die die jeweiligen Formen unseres Eingabebildes enthält.
Nach diesem Schritt werden wir alle primären Ausgaben und die Skip-Ausgaben sammeln, um sie an weitere Blöcke weiterzugeben. Wir erstellen den nächsten Block und konstruieren die gesamte Decoder-Architektur, bis wir die endgültige Ausgabe erreichen. Die Ausgabe wird die erforderlichen Dimensionen gemäß unserem gewünschten Ergebnis haben. In diesem Fall gibt es einen Ausgabeknoten mit der Sigmoid-Aktivierungsfunktion. Wir werden das funktionale API-Modellierungssystem aufrufen, um unser endgültiges Modell zu erstellen und es dem Benutzer zur Verfügung zu stellen, um beliebige Aufgaben mit der U-Net-Architektur auszuführen.
Implementierung des U-Net-Modells
def U_Net(Image_Size):
# Bildgröße und Form festlegen
input1 = Input(Image_Size)
# Konstruktion der Encoder-Blöcke
skip1, encoder_1 = encoder(input1, 64)
skip2, encoder_2 = encoder(encoder_1, 64*2)
skip3, encoder_3 = encoder(encoder_2, 64*4)
skip4, encoder_4 = encoder(encoder_3, 64*8)
# Vorbereitung des nächsten Blocks
conv_block = convolution_operation(encoder_4, 64*16)
# Konstruktion der Decoder-Blöcke
decoder_1 = decoder(conv_block, skip4, 64*8)
decoder_2 = decoder(decoder_1, skip3, 64*4)
decoder_3 = decoder(decoder_2, skip2, 64*2)
decoder_4 = decoder(decoder_3, skip1, 64)
out = Conv2D(1, 1, padding="same", activation="sigmoid")(decoder_4)
model = Model(input1, out)
return model
Finalisierung des U-Net-Modells
Stellen Sie sicher, dass Ihre Bildgrößen durch mindestens 16 oder Vielfache von 16 teilbar sind. Da wir während des Down-Samplings vier Max-Pooling-Schichten verwenden, möchten wir vermeiden, dass durch ungerade Zahlen teilbare Formen auftreten. Daher wäre es am besten, sicherzustellen, dass die Größen Ihrer Architektur den folgenden Größen entsprechen: (48, 48), (80, 80), (160, 160), (256, 256), (512, 512) und ähnliche Formate. Lassen Sie uns die Modellstruktur für eine Eingabeform von (160, 160, 3) testen. Eine Zusammenfassung des Modells sowie eine entsprechende grafische Darstellung werden erstellt. Diese Strukturen können in dem beigefügten Jupyter Notebook eingesehen werden. Zusätzlich wird die Datei model.png die vollständige architektonische Darstellung zeigen.
input_shape = (160, 160, 3)
model = U_Net(input_shape)
model.summary()
tf.keras.utils.plot_model(model, "model.png", show_shapes=False, show_dtype=False,
show_layer_names=True, rankdir='TB', expand_nested=False, dpi=96)
Mit den obigen Codeblöcken können Sie die Zusammenfassung und die grafische Darstellung des Modells einsehen. Lassen Sie uns nun ein spannendes Projekt mit der U-Net-Architektur erkunden.
Schnelles Beispielprojekt zur Leistungsanalyse von U-Net
Für dieses Projekt nutzen wir die Referenz von Keras für ein Bildsegmentierungsprojekt. Der folgende Link führt Sie zur Quelle. In diesem Projekt extrahieren wir das Dataset und visualisieren die grundlegenden Elemente, um einen Überblick über die Struktur zu erhalten. Anschließend erstellen wir den Daten-Generator für das Laden der Daten aus dem Dataset. Danach trainieren wir das zuvor erstellte U-Net-Modell, bis wir ein zufriedenstellendes Ergebnis erhalten. Sobald das gewünschte Ergebnis erzielt wurde, speichern wir dieses Modell und testen es mit einer Validierungsprobe. Lassen Sie uns mit der Implementierung des Projekts beginnen!
Vorbereitung des Datensatzes
Für diese spezielle Bildsegmentierungsaufgabe verwenden wir das Oxford Pet Dataset. Dieses Dataset umfasst 37 Kategorien von Haustieren mit jeweils etwa 200 Bildern pro Klasse. Die Bilder weisen große Variationen in Skalierung, Pose und Beleuchtung auf. Um das Dataset lokal auf Ihrem System zu installieren, können Sie die Bilddaten von diesem Link herunterladen und die Annotationsdaten von folgendem Link (TBA). Sobald Sie die Zip-Dateien erfolgreich heruntergeladen haben, können Sie sie mit 7-Zip oder einem ähnlichen Tool auf Ihrem Betriebssystem entpacken.
Definition der Datensatzpfade für die Bildsegmentierung
Im ersten Code-Block definieren wir die jeweiligen Pfade zu den Bilder- und Annotationsverzeichnissen. Zusätzlich legen wir einige grundlegende Parameter wie die Bildgröße, die Batch-Größe und die Anzahl der Klassen fest. Danach stellen wir sicher, dass alle Elemente im Datensatz in der richtigen Reihenfolge angeordnet sind, um eine reibungslose Bildsegmentierung zu ermöglichen. Sie können die Bilder mit den entsprechenden Annotationen überprüfen, indem Sie beide Dateipfade ausgeben und prüfen, ob sie die gewünschten Ergebnisse liefern.
Code zur Definition der Datensatzpfade
import os
input_dir = "images/"
target_dir = "annotations/trimaps/"
img_size = (160, 160)
num_classes = 3
batch_size = 8
input_img_paths = sorted(
[
os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")
]
)
target_img_paths = sorted(
[
os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")
]
)
print("Anzahl der Beispiele:", len(input_img_paths))
for input_path, target_path in zip(input_img_paths[:10], target_img_paths[:10]):
print(input_path, "|", target_path)
Datenvisualisierung
Nachdem wir unsere Daten für das Projekt gesammelt und vorverarbeitet haben, ist der nächste Schritt eine kurze Analyse des Datensatzes. Lassen Sie uns den Datensatz untersuchen, indem wir sowohl ein Bild als auch dessen entsprechende segmentierte Ausgabe anzeigen. Diese segmentierte Ausgabe mit der Maskierung wird oft als Ground-Truth-Annotation bezeichnet. Wir nutzen die I-Python-Anzeigefunktion zusammen mit der Pillow-Bibliothek, um ein zufällig ausgewähltes Bild darzustellen. Der zugehörige Code ist unten aufgeführt:
Code zur Visualisierung des Datensatzes
from IPython.display import Image, display
from tensorflow.keras.preprocessing.image import load_img
import PIL
from PIL import ImageOps
# Eingabebild #7 anzeigen
display(Image(filename=input_img_paths[9]))
# Auto-Kontrast-Version der entsprechenden Zielmaske anzeigen (pro-Pixel-Kategorien)
img = PIL.ImageOps.autocontrast(load_img(target_img_paths[9]))
display(img)


Konfiguration des Data Generators
In diesem Code-Block verwenden wir anstelle von regulären Daten-Generatoren die Sequence-Klasse aus dem Keras Deep-Learning-Framework. Diese Methode ist für das Multi-Processing deutlich sicherer als der klassische Generator-Ansatz, da jede Stichprobe pro Epoche nur einmal trainiert wird. Dadurch vermeiden wir unnötige Anpassungen, die die Datenintegrität beeinträchtigen könnten. Wir werden eine Sequence-Klasse im utils-Modul von Keras implementieren, um Daten zu laden, zu verarbeiten und in Batches zu vektorisieren. Im Folgenden definieren wir die Initialisierungsfunktion, eine Funktion zur Berechnung der Länge sowie eine Funktion zur Generierung der Datenbatches.
Implementierung der Keras Sequence-Klasse
from tensorflow import keras
import numpy as np
from tensorflow.keras.preprocessing.image import load_img
class OxfordPets(keras.utils.Sequence):
"""Hilfsklasse zur Iteration über die Daten (als Numpy-Arrays)."""
def __init__(self, batch_size, img_size, input_img_paths, target_img_paths):
self.batch_size = batch_size
self.img_size = img_size
self.input_img_paths = input_img_paths
self.target_img_paths = target_img_paths
def __len__(self):
return len(self.target_img_paths) // self.batch_size
def __getitem__(self, idx):
"""Gibt ein Tupel (Eingabe, Ziel) für das Batch mit Index idx zurück."""
i = idx * self.batch_size
batch_input_img_paths = self.input_img_paths[i : i + self.batch_size]
batch_target_img_paths = self.target_img_paths[i : i + self.batch_size]
x = np.zeros((self.batch_size,) + self.img_size + (3,), dtype="float32")
for j, path in enumerate(batch_input_img_paths):
img = load_img(path, target_size=self.img_size)
x[j] = img
y = np.zeros((self.batch_size,) + self.img_size + (1,), dtype="uint8")
for j, path in enumerate(batch_target_img_paths):
img = load_img(path, target_size=self.img_size, color_mode="grayscale")
y[j] = np.expand_dims(img, 2)
# Die Ground-Truth-Labels sind 1, 2, 3. Wir subtrahieren 1, um sie auf 0, 1, 2 zu setzen:
y[j] -= 1
return x, y
Aufteilung der Daten in Trainings- und Validierungs-Sets
Im nächsten Schritt definieren wir die Aufteilung zwischen Trainings- und Validierungsdaten. Dies stellt sicher, dass keine Datenkorruption zwischen den Trainings- und Testmengen auftritt. Es ist wichtig, dass diese Datensätze strikt getrennt bleiben, damit das Modell keinen Zugriff auf Testdaten während des Trainings erhält. Zusätzlich führen wir eine optionale Shuffle-Operation für den Validierungsdatensatz durch. Diese mischt alle Bilder, sodass wir zufällige Proben sowohl für das Training als auch für die Validierung erhalten. Danach speichern wir die Trainings- und Validierungswerte in den jeweiligen Variablen.
Code zur Datenaufteilung
import random
# Aufteilen der Bildpfade in Trainings- und Validierungssets
val_samples = 1000
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_img_paths)
train_input_img_paths = input_img_paths[:-val_samples]
train_target_img_paths = target_img_paths[:-val_samples]
val_input_img_paths = input_img_paths[-val_samples:]
val_target_img_paths = target_img_paths[-val_samples:]
# Erstellen der Keras Sequence-Instanzen für jede Aufteilung
train_gen = OxfordPets(
batch_size, img_size, train_input_img_paths, train_target_img_paths
)
val_gen = OxfordPets(batch_size, img_size, val_input_img_paths, val_target_img_paths)
Implementierung der Datenaufteilung
import random
# Aufteilen der Bildpfade in Trainings- und Validierungssets
val_samples = 1000
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_img_paths)
train_input_img_paths = input_img_paths[:-val_samples]
train_target_img_paths = target_img_paths[:-val_samples]
val_input_img_paths = input_img_paths[-val_samples:]
val_target_img_paths = target_img_paths[-val_samples:]
# Erstellen der Keras Sequence-Instanzen für jede Aufteilung
train_gen = OxfordPets(
batch_size, img_size, train_input_img_paths, train_target_img_paths
)
val_gen = OxfordPets(batch_size, img_size, val_input_img_paths, val_target_img_paths)
Nachdem wir diese Schritte abgeschlossen haben, können wir mit der Konstruktion unseres U-Net-Modells fortfahren.
U-Net Modell
Das U-Net Modell, das wir in diesem Abschnitt konstruieren, ist genau dieselbe Architektur, die in den vorherigen Abschnitten definiert wurde, mit einigen wenigen Änderungen, die wir gleich erläutern werden. Nach der Vorbereitung des Datensatzes können wir unser Modell entsprechend aufbauen. Das Modell verarbeitet die Bildgrößen und beginnt mit der Strukturierung der Architektur, durch die unsere Bilder geleitet werden.
Änderungen an der letzten Schicht im U-Net
out = Conv2D(3, 1, padding="same", activation="sigmoid")(decoder_4)
# Oder
out = Conv2D(num_classes, 1, padding="same", activation="sigmoid")(decoder_4)
Wir ändern die finale Schicht der U-Net-Architektur, um die Anzahl der Ausgabekanäle zu spezifizieren, die am Ende generiert werden. Beachte, dass man alternativ die SoftMax-Funktion verwenden könnte, um die finale Ausgabe für eine Multi-Klassen-Klassifikation zu generieren. In vielen Fällen liefert die Sigmoid-Aktivierung jedoch ebenfalls solide Ergebnisse.
Training des U-Net Modells
Im nächsten Schritt werden wir das Modell kompilieren und trainieren, um seine Leistung auf den Daten zu testen. Wir verwenden auch einen Checkpoint, um das Modell zu speichern, sodass wir in Zukunft Vorhersagen treffen können. Ich habe das Training nach 11 Epochen unterbrochen, da ich mit dem erzielten Ergebnis zufrieden war. Du kannst jedoch entscheiden, das Training für weitere Epochen fortzusetzen.
Training des U-Net Modells
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy")
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation.h5", save_best_only=True)
]
# Trainiere das Modell mit Validierung nach jeder Epoche
epochs = 15
model.fit(train_gen, epochs=epochs, validation_data=val_gen, callbacks=callbacks)
Trainingsfortschritt
Epoch 1/15
798/798 [==============================] - 874s 1s/step - loss: 0.7482 - val_loss: 0.7945
Epoch 2/15
798/798 [==============================] - 771s 963ms/step - loss: 0.4964 - val_loss: 0.5646
Epoch 3/15
798/798 [==============================] - 776s 969ms/step - loss: 0.4039 - val_loss: 0.3900
Epoch 4/15
798/798 [==============================] - 776s 969ms/step - loss: 0.3582 - val_loss: 0.3574
Epoch 5/15
798/798 [==============================] - 788s 985ms/step - loss: 0.3335 - val_loss: 0.3607
Epoch 6/15
798/798 [==============================] - 778s 972ms/step - loss: 0.3078 - val_loss: 0.3916
Epoch 7/15
798/798 [==============================] - 780s 974ms/step - loss: 0.2772 - val_loss: 0.3226
Epoch 8/15
798/798 [==============================] - 796s 994ms/step - loss: 0.2651 - val_loss: 0.3046
Epoch 9/15
798/798 [==============================] - 802s 1s/step - loss: 0.2487 - val_loss: 0.2996
Epoch 10/15
798/798 [==============================] - 807s 1s/step - loss: 0.2335 - val_loss: 0.3020
Epoch 11/15
798/798 [==============================] - 797s 995ms/step - loss: 0.2220 - val_loss: 0.2801
Ergebnisse anzeigen
Zum Abschluss visualisieren wir die erzielten Ergebnisse.
# Generiere Vorhersagen für alle Bilder im Validierungsset
val_gen = OxfordPets(batch_size, img_size, val_input_img_paths, val_target_img_paths)
val_preds = model.predict(val_gen)
def display_mask(i):
"""Hilfsfunktion zur Anzeige einer Modellvorhersage."""
mask = np.argmax(val_preds[i], axis=-1)
mask = np.expand_dims(mask, axis=-1)
img = PIL.ImageOps.autocontrast(keras.preprocessing.image.array_to_img(mask))
display(img)
# Ergebnisse für Validierungsbild #10 anzeigen
i = 10
# Eingabebild anzeigen
display(Image(filename=val_input_img_paths[i]))
# Ground-Truth-Zielmaske anzeigen
img = PIL.ImageOps.autocontrast(load_img(val_target_img_paths[i]))
display(img)
# Vom Modell vorhergesagte Maske anzeigen
display_mask(i) # Beachte, dass das Modell nur Eingaben mit 150x150 sieht.



Fazit
Die U-Net-Architektur ist eines der bedeutendsten und revolutionärsten Meilensteine im Bereich des Deep Learning. Während das ursprüngliche Forschungspapier, das die U-Net-Architektur vorstellte, zur Lösung der Aufgabe der biomedizinischen Bildsegmentierung entwickelt wurde, beschränkt sich die Anwendung nicht nur auf diesen Bereich. Das Modell kann auch weiterhin die komplexesten Probleme im Bereich Deep Learning lösen. Obwohl einige Elemente der ursprünglichen Architektur inzwischen veraltet sind, gibt es zahlreiche Varianten dieser Architektur. Dazu gehören LadderNet, U-Net mit Attention-Mechanismen, das rekurrente und residuelle U-Net (R2-UNet) sowie andere Netzwerke, die erfolgreich aus den ursprünglichen U-Net-Modellen abgeleitet wurden.
Zusammenfassung der wichtigsten Erkenntnisse
In diesem Artikel haben wir eine kurze Einführung in die U-Net-Modellierungstechnik erhalten, die in modernen Aufgaben der Bildsegmentierung eine herausragende Rolle spielt. Anschließend haben wir die Konstruktion und die zentralen Methoden zur Entwicklung der U-Net-Architektur detailliert untersucht. Wir haben verschiedene Methoden und Techniken analysiert, um die bestmöglichen Ergebnisse auf dem bereitgestellten Datensatz zu erzielen. Im weiteren Verlauf haben wir gelernt, wie man die U-Net-Architektur von Grund auf mit verschiedenen Blöcken erstellt, um die Gesamtstruktur zu vereinfachen. Abschließend haben wir das erstellte U-Net-Modell anhand eines einfachen Beispielproblems zur Bildsegmentierung getestet.
Wie geht es weiter? CANet für Bildsegmentierung
Im nächsten Artikel werden wir uns mit der CANet-Architektur für Bildsegmentierung beschäftigen und einige ihrer wichtigsten Konzepte verstehen. Anschließend werden wir die gesamte Architektur von Grund auf neu erstellen. Bis dahin viel Spaß beim Lernen und Erkunden der Welt des Deep Learning!
