
Modelle, die das Deep Learning geprägt haben: 2015-2016
In diesem Artikel betrachten wir Modelle aus den Jahren 2015-2016, die große Fortschritte ermöglichten. In nur zwei Jahren verbesserten sie Genauigkeit und Leistung erheblich. Konkret werfen wir einen Blick auf:
ResNet
Wide ResNet
InceptionV3
SqueezeNet
Legen wir los.
Voraussetzungen
Du solltest folgende Kenntnisse mitbringen:
– Grundlagen von Convolutional Neural Networks (CNNs) und Deep Learning.
– Verständnis für Backpropagation und Gradient Descent.
– Wissen über verschiedene Netzwerkschichten (z. B. Convolutional, Pooling, Fully Connected).
– Erfahrung mit Deep-Learning-Frameworks wie PyTorch oder TensorFlow.
ResNet
Tiefe neuronale Netzwerke brauchen lange für das Training und neigen zum Overfitting. Um dieses Problem zu lösen, entwickelte Microsoft ein Residual Learning Framework. Ihr Forschungspapier Deep Residual Learning for Image Recognition erschien 2015. Daraus entstand ResNet („Residual Network“).
Ein Problem tiefer Netzwerke: Ab einer bestimmten Tiefe steigt die Fehlerrate. Dies nennt man das „Degradationsproblem“. Nicht jede Architektur lässt sich gleich gut optimieren.
ResNet setzt auf „Residual Mapping“. Statt jede Schicht direkt an eine Zielabbildung anzupassen, lernt sie Residual-Werte. Das folgende Bild zeigt das Grundelement eines Residual-Netzwerks.
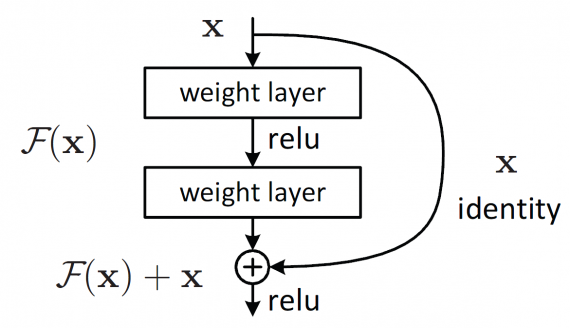
Die Berechnung F(x) + x erfolgt über Shortcut-Verbindungen in einem neuronalen Netz.
ResNet verbessert Optimierbarkeit und Genauigkeit tiefer Netzwerke. Das Modell erzielte bereits mit ImageNet (1,2 Millionen Bilder in 1000 Klassen) sehr gute Ergebnisse.
ResNet Architektur
Im Vergleich zu herkömmlichen Netzwerken bleibt ResNet übersichtlich. Das Bild unten zeigt ein VGG-Netzwerk, ein normales 34-Schichten-Netzwerk und ein 34-Schichten-Residual-Netzwerk. Klassische Netzwerke verwenden gleiche Filterzahlen pro Feature-Map. Sobald sich die Feature-Map halbiert, verdoppelt sich die Anzahl der Filter. Das macht das Training schwieriger.
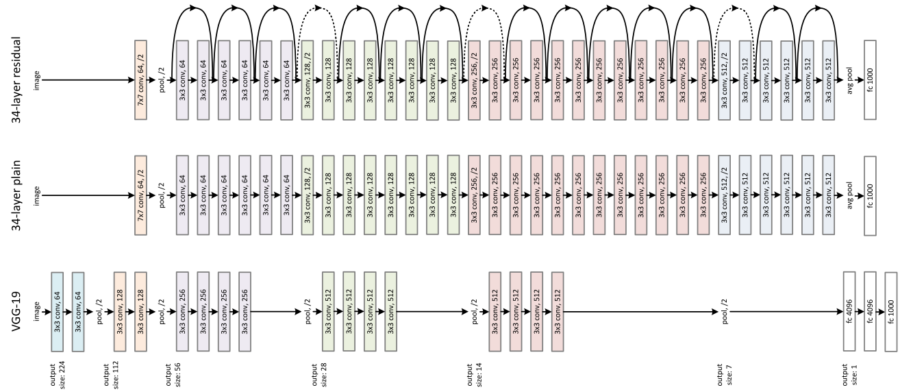
Das Residual-Netzwerk benötigt weniger Filter und bleibt einfacher zu trainieren. Eine Shortcut-Verbindung erzeugt die Residual-Variante. Sie führt eine Identitätsabbildung durch und ergänzt Nullen für Dimensionsvergrößerung. Mathematisch entspricht dies F(x{W} + x), berechnet mit 1×1-Convolutions.
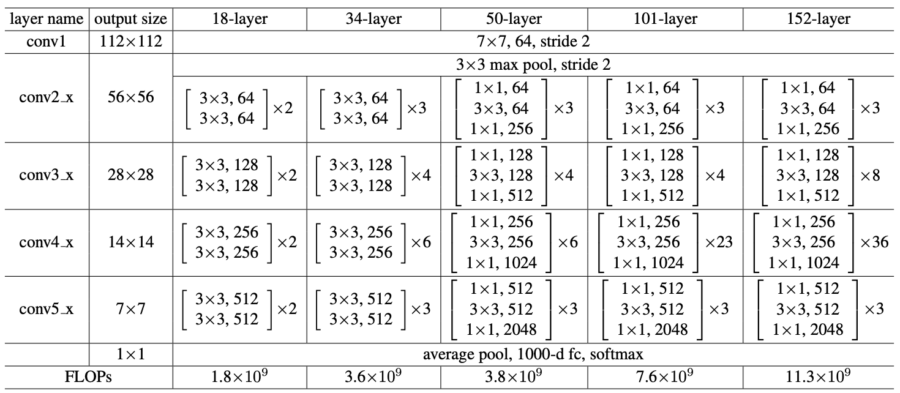
Jeder ResNet-Block umfasst zwei (ResNet-18, ResNet-34) oder drei (ResNet-50, ResNet-101, ResNet-152) Schichten.
ResNet Training und Ergebnisse
ImageNet-Bilder wurden auf 224 × 224 skaliert und normalisiert. Für das Training kam der Stochastic Gradient Descent mit einer Mini-Batch-Größe von 256 zum Einsatz. Die Lernrate startete bei 0,1 und sank um den Faktor 10, sobald der Fehler stieg. Insgesamt lief das Training über 600.000 Iterationen. Weight Decay und Momentum lagen bei 0,0001 bzw. 0,9. Dropout-Schichten entfielen.
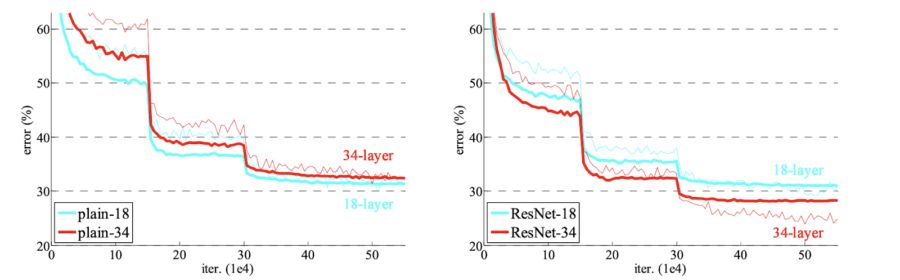
ResNet performt in tiefen Architekturen hervorragend. Das folgende Bild zeigt Fehlerraten von 18- und 34-Schichten-Netzwerken. Links normale Netzwerke, rechts ihre ResNet-Pendants. Die rote Kurve markiert den Trainingsfehler, die dicke Kurve den Validierungsfehler.
Die folgende Tabelle zeigt die Top-1-Fehlerrate (%, 10-Crop-Tests) auf ImageNet:
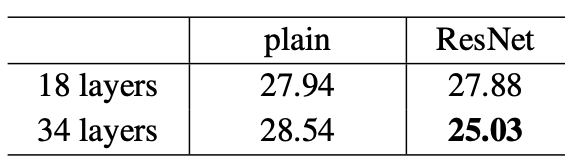
ResNet setzte neue Maßstäbe für Deep Learning.
Hier einige nützliche Links zur Implementierung von ResNet:
PyTorch ResNet Implementierung
Originales Forschungspapier
Wide ResNet
Wide Residual Networks verbessern ResNet durch mehr Breite statt Tiefe. Das Paper Wide Residual Networks (2016) beschreibt die Methode.
Wide ResNet Architektur
Ein Wide ResNet setzt auf mehrere ResNet-Blöcke mit einer BatchNormalization-ReLU-Conv-Struktur:
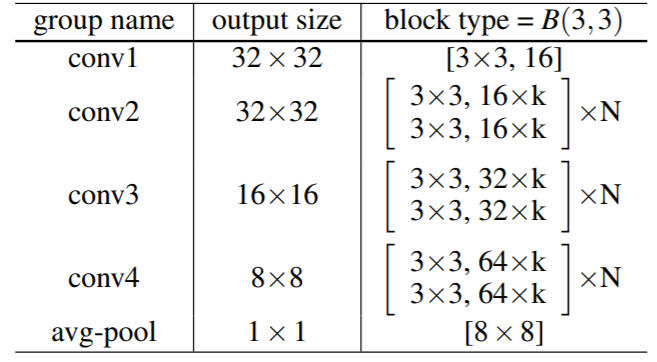
Wide ResNet Training und Ergebnisse
Das Modell lief auf CIFAR-10 mit diesen Parametern:
- Faltungstyp: B(3, 3)
- Faltungen pro ResNet-Block: 2
- Optimale Tiefe: 28, Breite: 10
- Dropout senkte den Fehler weiter
Die folgende Tabelle vergleicht Wide ResNet mit anderen Modellen auf CIFAR-10 und CIFAR-100:
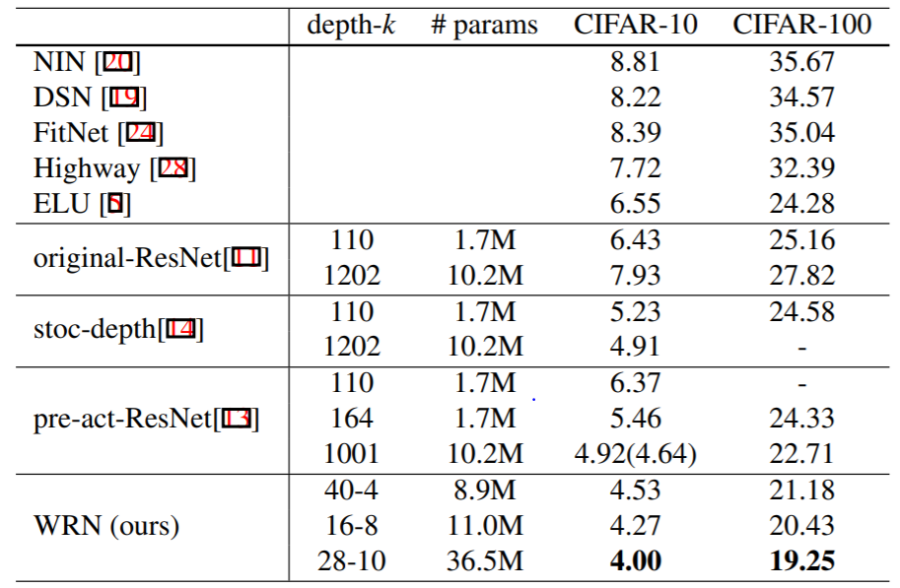
Nützliche Links zur Wide ResNet-Implementierung:
Original-Paper
PyTorch Wide ResNet
TensorFlow Wide ResNet
Inception v3
Inception v3 optimiert frühere Inception-Architekturen und reduziert die benötigte Rechenleistung. Das Paper Rethinking the Inception Architecture for Computer Vision (2015) beschreibt die Methode. Autoren sind Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe und Jonathon Shlens.
Im Vergleich zu VGGNet benötigen Inception-Netzwerke (GoogLeNet/Inception v1) weniger Speicher und Rechenkapazität. Anpassungen müssen jedoch so erfolgen, dass diese Effizienz erhalten bleibt.
Inception v3 verwendet mehrere Optimierungen:
- Faktorisierte Faltungen
- Regularisierung
- Dimensionsreduktion
- Parallelisierte Berechnungen
Inception v3 Architektur
Die Architektur von Inception v3 baut sich schrittweise auf:
- Faktorisierte Faltungen: Sie verringern die Anzahl der Parameter und halten das Modell effizient.
- Kleinere Faltungen: Größere Faltungen werden durch kleinere ersetzt, um das Training zu beschleunigen. Beispielsweise lassen sich 5×5-Filter durch zwei aufeinanderfolgende 3×3-Filter mit weniger Parametern ersetzen.
- Asymmetrische Faltungen: Eine 3×3-Faltung kann durch eine Kombination aus 1×3- und 3×1-Faltung ersetzt werden.
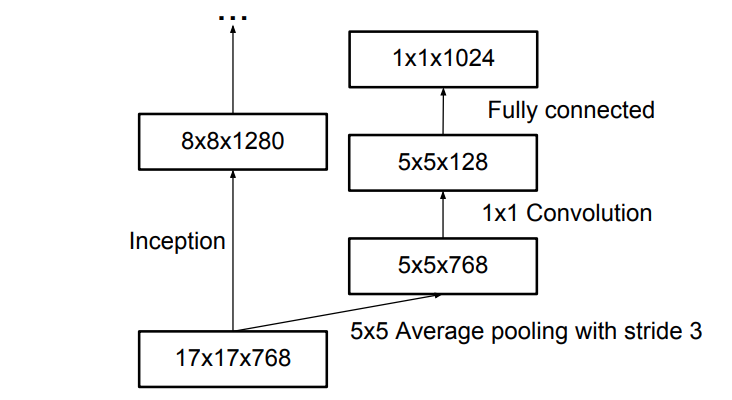
- Auxiliary Classifier: Ein zusätzlicher kleiner CNN-Klassifikator hilft während des Trainings, indem er zusätzliche Verlustfunktionen integriert.
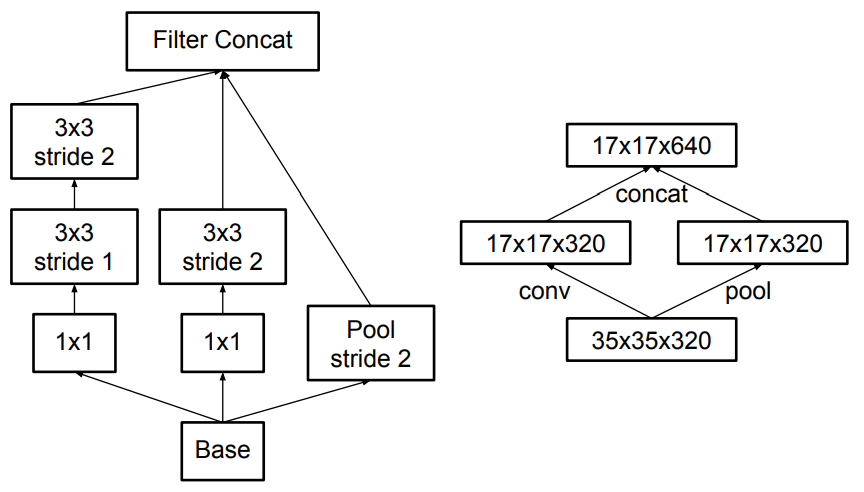
Die finale Architektur kombiniert alle diese Techniken:
 Inception v3 Training und Ergebnisse
Inception v3 Training und Ergebnisse
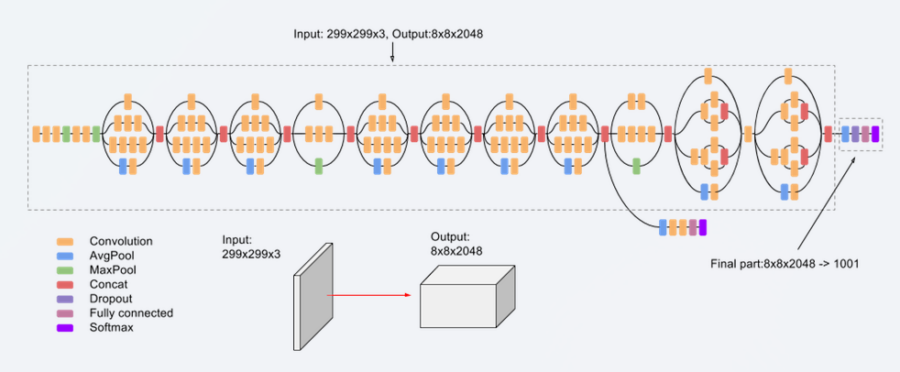 Inception v3 Training und Ergebnisse
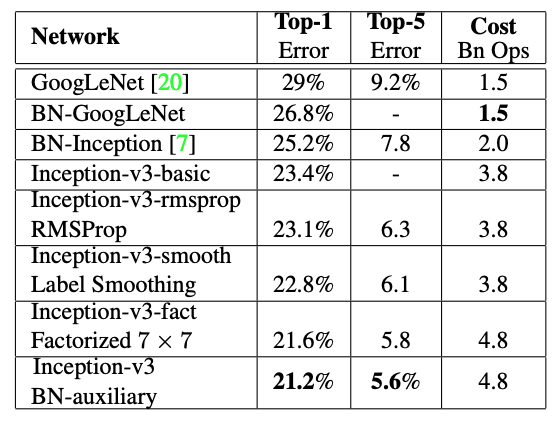
Inception v3 Training und ErgebnisseInception v3 lief auf ImageNet und erzielte im Vergleich mit anderen Modellen bessere Fehlerraten. Die folgende Tabelle zeigt, dass das Modell mit Auxiliary Classifier, faktorisierter Faltung, RMSProp und Label Smoothing die besten Ergebnisse lieferte.
Hier einige nützliche Links zur Implementierung von Inception v3:
Original-Paper
PyTorch Inception v3
SqueezeNet
SqueezeNet ist eine kompakte Alternative zu AlexNet. Es benötigt fast 50-mal weniger Parameter und läuft dreimal schneller. Forscher von DeepScale, der University of California, Berkeley, und Stanford entwickelten das Modell. Das Paper SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size beschreibt die Methode.
Die Hauptideen von SqueezeNet:
- Verwendung von 1×1- statt 3×3-Filtern
- Reduktion der Eingangs-Kanäle für 3×3-Filter
- Spätes Downsampling für größere Aktivierungskarten
SqueezeNet Architektur und Ergebnisse
SqueezeNet kombiniert „Squeeze“- und „Expand“-Schichten. Eine „Squeeze“-Schicht enthält nur 1×1-Filter. Eine „Expand“-Schicht erweitert sie mit 1×1- und 3×3-Filtern.
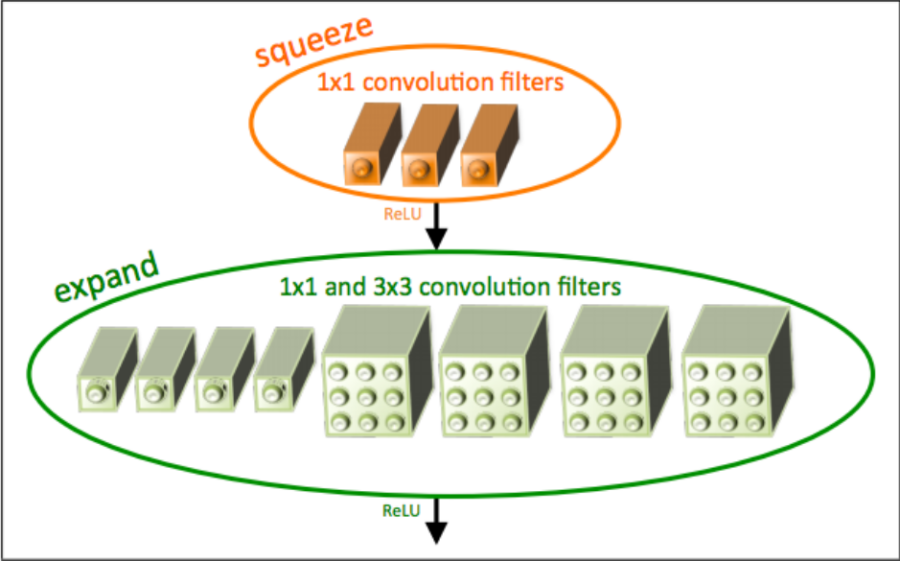
Das „Fire-Modul“
Das Fire-Modul kombiniert eine „Squeeze“-Schicht mit einer „Expand“-Schicht. Zunächst verarbeitet eine eigenständige Faltungsschicht das Eingangsbild. Danach folgen acht Fire-Module („fire2-9“).
Unten der Vergleich zwischen SqueezeNet und AlexNet:
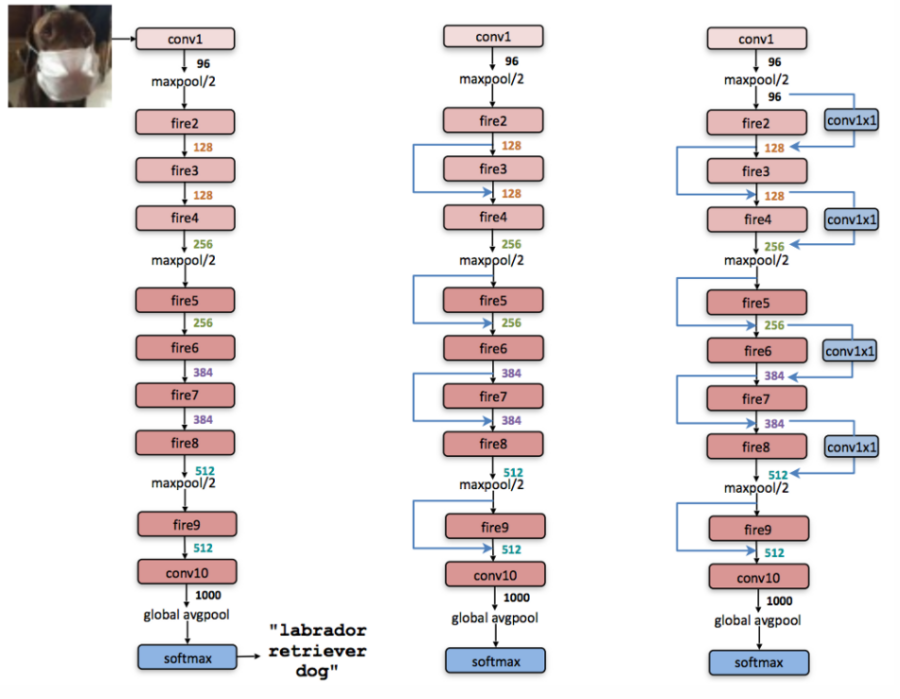
Von links nach rechts: SqueezeNet, SqueezeNet mit einfacher Bypass-Verbindung und SqueezeNet mit komplexer Bypass-Verbindung.
Strategie Zwei erhöht die Anzahl der Filter pro Fire-Modul mit einer einfachen Bypass-Verbindung. Strategy Drei setzt das Pooling später, wodurch die Architektur mit einer komplexen Bypass-Verbindung (ganz rechts) entsteht.
Hier der Leistungsvergleich mit AlexNet:
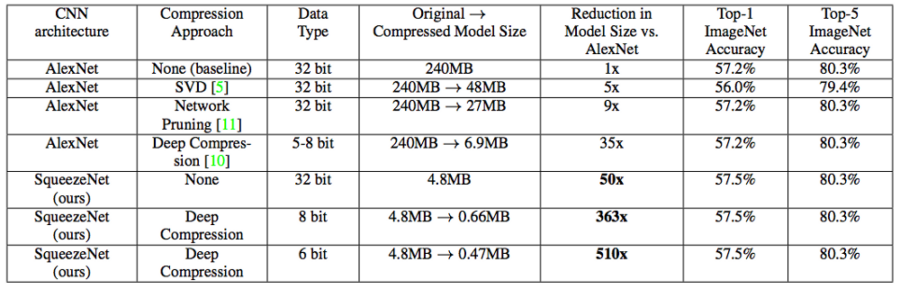
AlexNet verbrauchte 240 MB Speicher und erreichte 80,3 % Genauigkeit. Die komprimierte Version von SqueezeNet benötigte nur 0,47 MB und erzielte dieselbe Leistung.
Zusätzliche Netzwerkparameter
- Zwischen allen „Squeeze“- und „Expand“-Schichten kommt eine ReLU-Aktivierung zum Einsatz.
- Dropout (p = 0.5) nach Fire9 reduziert Overfitting.
- Das Netzwerk verwendet keine vollständig verbundenen Schichten. Diese Entscheidung basiert auf der Network In Network (NIN)-Architektur.
- Die Lernrate startet bei 0,04 und sinkt linear im Training.
- Das Modell nutzt Adam als Optimierer.
SqueezeNet erleichtert den Einsatz in Anwendungen, die geringe Modellgrößen erfordern. Das Modell startete in Caffe und fand inzwischen Verbreitung auf vielen Plattformen.
Nützliche Links zur Implementierung:
Original-Code
Original-Paper
SqueezeNet in TensorFlow
SqueezeNet in PyTorch
Fazit
ResNet, Wide ResNet, Inception v3 und SqueezeNet haben das Deep Learning revolutioniert. Jedes Modell brachte neue Ideen für effizientere und leistungsfähigere neuronale Netzwerke.
