
Quantile() Funktion in R – Unverzichtbarer Leitfaden
Sie können die Stichprobenquantile mit der Funktion quantile() in R erzeugen.
Hallo Leute, heute werden wir uns anschauen, wie man die Quantile der Werte mit der Funktion quantile() findet.
Quantil: In Laienbegriffen ist ein Quantil nichts anderes als eine Stichprobe, die in gleich große Gruppen oder Größen aufgeteilt ist. Aufgrund dieser Eigenschaft werden die Quantile auch als Fraktile bezeichnet. Bei den Quantilen wird das 25. Perzentil als unteres Quartil, das 50. Perzentil als Median und das 75. Perzentil als oberes Quartil bezeichnet.
In den folgenden Abschnitten sehen wir uns an, wie diese Quantile()-Funktion in R funktioniert.
Syntax der Quantile()-Funktion
Die Syntax der Quantile()-Funktion in R lautet:
quantile(x, probs = , na.rm = FALSE)
Wo,
- X = der Eingabevektor oder die Werte
- Probs = Wahrscheinlichkeiten der Werte zwischen 0 und 1.
- na.rm = entfernt die NA-Werte.
Eine einfache Implementierung der Quantile()-Funktion in R
Nun, ich hoffe, Sie sind mit der Definition und den Erklärungen zur Quantilfunktion vertraut. Jetzt sehen wir uns an, wie die Quantilfunktion in R mit Hilfe eines einfachen Beispiels funktioniert, das die Quantile für die Eingabedaten zurückgibt.
#creates a vector having some values and the quantile function will return the percentiles for the data.
df<-c(12,3,4,56,78,18,46,78,100)
quantile(df)
Output:
0% 25% 50% 75% 100%
3 12 46 78 100
In der obigen Stichprobe können Sie beobachten, dass die Quantile-Funktion zuerst die Eingabewerte in aufsteigender Reihenfolge anordnet und dann die erforderlichen Perzentile der Werte zurückgibt.
Hinweis: Die Quantilfunktion teilt die Daten in zwei gleiche Hälften, wobei der Median in der Mitte liegt und darüber der untere Teil als unteres Quartil und der obere Teil als oberes Quartil bezeichnet wird.
Umgang mit fehlenden Werten – ‘NaN’
NaNs sind überall. In dieser datengetriebenen digitalen Welt begegnen Sie diesen NaNs häufiger, die oft als fehlende Werte bezeichnet werden. Wenn Ihre Daten auf irgendeine Weise diese fehlenden Werte enthalten, können Sie am Ende NaNs in der Ausgabe oder Fehler in der Ausgabe bekommen.
Um diese fehlenden Werte zu behandeln, verwenden wir die na.rm-Funktion. Diese Funktion entfernt die NA-Werte aus unseren Daten und gibt die wahren Werte zurück.
Lassen Sie uns sehen, wie das funktioniert.
#creates a vector having values along with NaN's
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df)
Output:
Error in quantile.default(df) :
missing values and NaN's not allowed if 'na.rm' is FALSE
Oh, wir haben einen Fehler erhalten. Wenn Ihre Vermutung die NA-Werte betrifft, sind Sie absolut klug. Wenn NA-Werte in unseren Daten vorhanden sind, enden die meisten Funktionen damit, die NA-Werte selbst oder die oben genannte Fehlermeldung zurückzugeben.
Nun, entfernen wir diese fehlenden Werte mit der na.rm-Funktion.
#creates a vector having values along with NaN's
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
#removes the NA values and returns the percentiles
quantile(df,na.rm = TRUE)
Output:
0% 25% 50% 75% 100%
3 12 46 78 100
In der obigen Stichprobe können Sie die na.rm-Funktion und ihre Auswirkungen auf das Ergebnis sehen. Die Funktion entfernt die NAs, um falsche Ergebnisse zu vermeiden.
Das ‘Probs’-Argument in der Quantile
Wie Sie das Probs-Argument in der Syntax sehen können, das im ersten Abschnitt des Artikels vorgestellt wurde, fragen Sie sich vielleicht, was es bedeutet und wie es funktioniert. Nun, das Probs-Argument wird an die Quantile-Funktion übergeben, um die spezifischen oder benutzerdefinierten Perzentile zu erhalten.
Scheint kompliziert? Keine Sorge, ich werde es in einfache Begriffe zerlegen.
Immer wenn Sie die Funktion Quantile verwenden, gibt sie die Standardperzentile wie 25, 50 und 75 Perzentile zurück. Aber was ist, wenn Sie das 47. Perzentil oder vielleicht das 88. Perzentil wollen?
Dann kommt das Argument ‘Probs’ ins Spiel, in dem Sie die gewünschten Perzentile angeben können.
Bevor wir zum Beispiel gehen, sollten Sie einige Dinge über das Probs-Argument wissen.
Probs: Das Probs- oder Wahrscheinlichkeitsargument sollte zwischen 0 und 1 liegen.
Hier ist eine Stichprobe, die die obige Aussage veranschaulicht.
#creates the vector of values
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
#returns the quantile of 22 and 77 th percentiles.
quantile(df,na.rm = T,probs = c(22,77))
Output:
Error in quantile.default(df, na.rm = T, probs = c(22, 77)) :
'probs' outside [0,1]
Oh, es ist ein Fehler!
Haben Sie verstanden, was passiert ist?
Hier kommt die Probs-Aussage. Obwohl wir die richtigen Werte im Probs-Argument angegeben haben, verletzt es die 0-1-Bedingung. Das Probs-Argument sollte Werte enthalten, die zwischen 0 und 1 liegen.
Also müssen wir die Probs 22 und 77 in 0,22 und 0,77 umwandeln. Jetzt liegen die Eingabewerte zwischen 0 und 1, richtig? Ich hoffe, das ergibt Sinn.
#creates a vector of values
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
#returns the 22 and 77th percentiles of the input values
quantile(df,na.rm = T,probs = c(0.22,0.77))
Output:
22% 77%
10.08 78.00
Die ‘Unname’-Funktion und ihre Verwendung
Angenommen, Sie möchten, dass Ihr Code nur die Perzentile zurückgibt und die Schnittpunkte vermeidet. In diesen Situationen können Sie die ‘unname’-Funktion verwenden.
Die ‘unname’-Funktion entfernt die Überschriften oder Schnittpunkte (0%, 25%, 50%, 75%, 100%) und gibt nur die Perzentile zurück.
Lassen Sie uns sehen, wie es funktioniert!
#creates a vector of values
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df,na.rm = T,probs = c(0.22,0.77))
#avoids the cut-points and returns only the percentiles.
unname(quantile(df,na.rm = T,probs = c(0.22,0.77)))
Output:
10.08 78.00
Jetzt können Sie beobachten, dass die Schnittpunkte durch die Unname-Funktion deaktiviert oder entfernt wurden und nur die Perzentile zurückgegeben werden.
Die ‘round’-Funktion und ihre Verwendung
Wir haben die Round-Funktion in R bereits in einem früheren Artikel ausführlich besprochen. Jetzt werden wir die Round-Funktion verwenden, um die Werte abzurunden.
Lassen Sie uns sehen, wie das funktioniert!
#creates a vector of values
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df,na.rm = T,probs = c(0.22,0.77))
#returns the round off values
unname(round(quantile(df,na.rm = T,probs = c(0.22,0.77))))
Output:
10 78
Wie Sie sehen können, sind unsere Ausgabewerte auf null Dezimalstellen gerundet.
Die Quantile für mehrere Gruppen/Spalten in einem Datensatz erhalten
Bis jetzt haben wir die Quantile-Funktion, ihre Verwendung und Anwendungen sowie ihre Argumente und deren korrekte Verwendung besprochen.
In diesem Abschnitt werden wir die Quantile für mehrere Spalten in einem Datensatz erhalten. Klingt interessant? Folgen Sie mir!
Ich werde den ‘mtcars’-Datensatz für diesen Zweck verwenden und auch die ‘dplyr’-Bibliothek dafür nutzen.
#reads the data
data("mtcars")
#returns the top few rows of the data
head(mtcars)
#install required paclages
install.packages('dplyr')
library(dplyr)
#using tapply, we can apply the function to multiple groups
do.call("rbind",tapply(mtcars$mpg, mtcars$gear, quantile))
Output:
0% 25% 50% 75% 100%
3 10.4 14.5 15.5 18.400 21.5
4 17.8 21.0 22.8 28.075 33.9
5 15.0 15.8 19.7 26.000 30.4
Im obigen Prozess müssen wir das ‘dplyr’-Paket installieren und dann die tapply- und rbind-Funktionen verwenden, um die mehreren Spalten der mtcars-Datensätze zu erhalten.
Im obigen Abschnitt haben wir mehrere Spalten wie ‘mpg’ und die ‘gear’-Spalten im mtcars-Datensatz genommen. So können wir die Quantile für mehrere Gruppen in einem Datensatz berechnen.
Können wir die Perzentile visualisieren?
Meine Antwort ist ein großes JA!. Das beste Diagramm dafür wäre ein Boxplot. Lassen Sie mich den Iris-Datensatz nehmen und versuchen, den Boxplot zu visualisieren, der die Perzentile ebenfalls darstellt.
Lassen Sie uns beginnen!
data(iris)
head(iris)
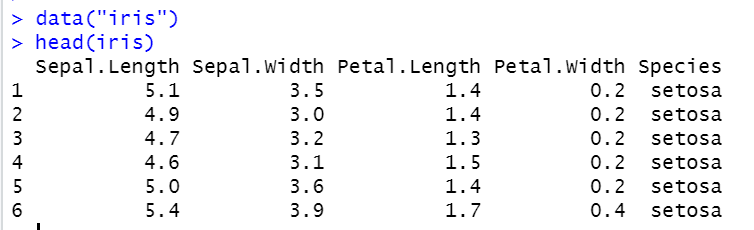
Dies ist der Iris-Datensatz mit den obersten 6 Werten.
Lassen Sie uns die Daten mit der Funktion namens – ‘Summary’ erkunden.
summary(iris)
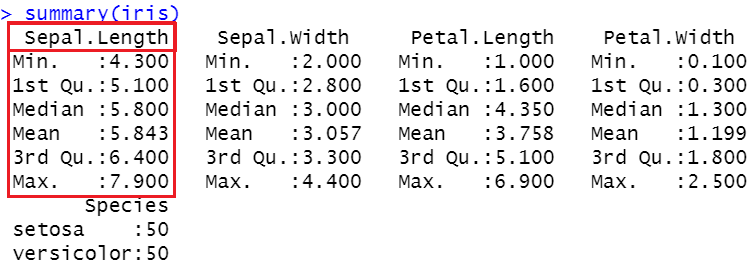
Im obigen Bild können Sie den Mittelwert, Median, 25. Perzentil (1. Quartil), 75. Perzentil (3. Perzentil) sowie die Min- und Max-Werte sehen. Lassen Sie uns diese Informationen durch einen Boxplot darstellen.
Lassen Sie uns das tun!
#plots a boxplot with labels
boxplot(iris$Sepal.Length, main='The boxplot showing the percentiles', col='Orange', ylab='Values', xlab='Sepal Length', border = 'brown', horizontal = T)
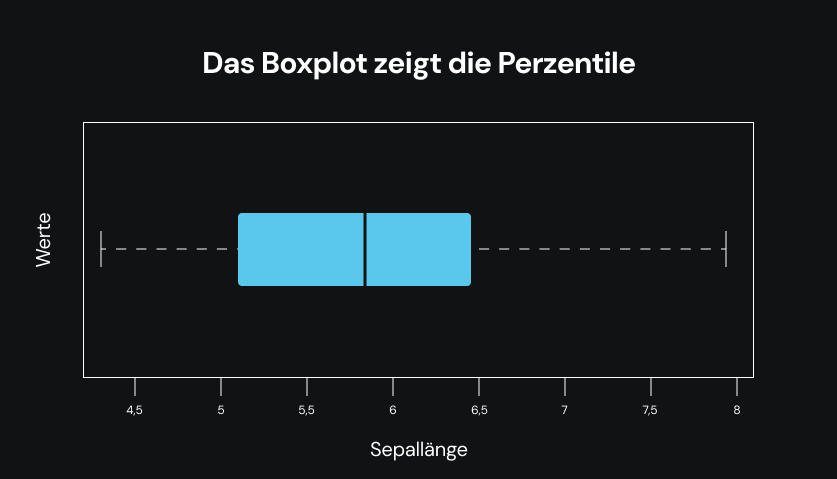
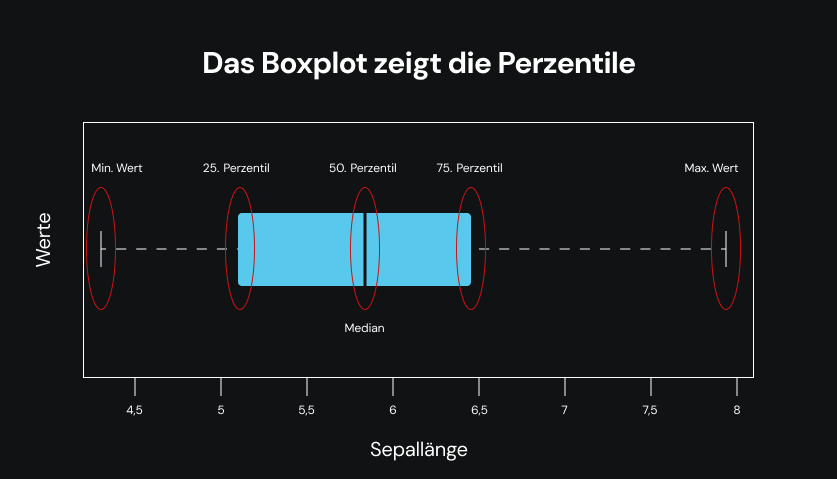
Ein Boxplot kann viele Aspekte der Daten zeigen. In der untenstehenden Abbildung habe ich die speziellen Werte erwähnt, die durch die Boxplots dargestellt werden. Das wird Ihnen Zeit sparen und Ihr Verständnis auf bestmögliche Weise erleichtern.
Quantile() Funktion in R – Zusammenfassung
Nun, das ist ein längerer Artikel, wie ich vermute. Und ich habe mein Bestes gegeben, um die Quantile()-Funktion in R in mehreren Dimensionen durch verschiedene Beispiele und Illustrationen zu erklären und zu erforschen. Die Quantile-Funktion ist die nützlichste Funktion in der Datenanalyse, da sie effizient mehr Informationen über die gegebenen Daten offenbart.
Ich hoffe, Sie haben ein gutes Verständnis für die Aufregung rund um die Quantile()-Funktion in R erlangt. Das ist alles für jetzt. Wir werden mit immer mehr schönen Funktionen und Themen in der R-Programmierung zurückkommen. Bis dahin passen Sie auf sich auf und viel Spaß bei der Datenanalyse!!! Quantile() Funktion in R – Unverzichtbarer Leitfaden
