
Node JS Architecture – Leitfaden
Bevor wir einige Node JS Programmierbeispiele starten, ist es wichtig, eine Vorstellung von der Node JS Architektur zu haben. Wir werden diskutieren, wie Node JS unter der Haube funktioniert, welchem Verarbeitungsmodell es folgt, wie Node JS gleichzeitige Anfragen mit einem Single-Threaded Modell handhabt usw.
Node JS Single Threaded Event Loop Modell
Wie bereits besprochen, verwenden Node JS Anwendungen die „Single Threaded Event Loop“ Architektur, um mehrere gleichzeitige Clients zu handhaben. Es gibt viele Webanwendungstechnologien wie JSP, Spring MVC, ASP.NET, HTML, Ajax, jQuery usw. Aber all diese Technologien folgen der „Multi-Threaded Request-Response“ Architektur, um mehrere gleichzeitige Clients zu handhaben. Wir sind bereits mit der „Multi-Threaded Request-Response“ Architektur vertraut, da sie von den meisten Webanwendungsframeworks verwendet wird. Aber warum hat die Node JS Plattform eine andere Architektur gewählt, um Webanwendungen zu entwickeln. Was sind die wichtigsten Unterschiede zwischen der Multithreaded- und der Single-Threaded Event-Loop-Architektur. Jeder Webentwickler kann Node JS lernen und sehr einfach Anwendungen entwickeln. Ohne ein Verständnis der Node JS Interna können wir jedoch keine Node JS Anwendungen sehr gut entwerfen und entwickeln. Also, bevor wir mit der Entwicklung von Node JS Anwendungen beginnen, werden wir zuerst die Interna der Node JS Plattform lernen.
Node JS Plattform
Die Node JS Plattform verwendet die „Single Threaded Event Loop“ Architektur, um mehrere gleichzeitige Clients zu handhaben. Aber wie handhabt sie wirklich gleichzeitige Clientanfragen ohne die Verwendung von mehreren Threads. Was ist das Event-Loop-Modell? Wir werden diese Konzepte nacheinander diskutieren. Bevor wir die „Single Threaded Event Loop“ Architektur diskutieren, werden wir zuerst die bekannte „Multi-Threaded Request-Response“ Architektur durchgehen.
Traditionelles Webanwendungs-Verarbeitungsmodell
Jede Webanwendung, die ohne Node JS entwickelt wurde, folgt typischerweise dem „Multi-Threaded Request-Response“ Modell. Einfach ausgedrückt können wir dieses Modell als Request/Response Modell bezeichnen. Der Client sendet eine Anfrage an den Server, dann verarbeitet der Server die Anfrage des Clients, bereitet eine Antwort vor und sendet sie zurück an den Client. Dieses Modell verwendet das HTTP-Protokoll. Da HTTP ein zustandsloses Protokoll ist, ist auch dieses Request/Response-Modell ein zustandsloses Modell. Daher können wir dies als Request/Response zustandsloses Modell bezeichnen. Dieses Modell verwendet jedoch mehrere Threads, um gleichzeitige Clientanfragen zu handhaben. Bevor wir die Interna dieses Modells besprechen, gehen wir zuerst durch das Diagramm unten. Verarbeitungsschritte des Request/Response-Modells:
- Clients senden Anfragen an den Webserver.
- Der Webserver verwaltet intern einen begrenzten Thread-Pool, um Dienste für die Clientanfragen zu bieten.
- Der Webserver befindet sich in einer endlosen Schleife und wartet auf eingehende Anfragen von Clients.
- Der Webserver empfängt diese Anfragen.
- Der Webserver nimmt eine Clientanfrage auf.
- Nimmt einen Thread aus dem Thread-Pool.
- Weist diesen Thread der Clientanfrage zu.
- Dieser Thread kümmert sich um das Lesen der Clientanfrage, die Verarbeitung der Clientanfrage, die Durchführung von Blocking-IO-Operationen (falls erforderlich) und die Vorbereitung der Antwort.
- Dieser Thread sendet die vorbereitete Antwort zurück an den Webserver.
- Der Webserver sendet diese Antwort wiederum an den entsprechenden Client.
Der Server wartet in einer endlosen Schleife und führt alle oben genannten Teilschritte für alle n Clients aus. Das bedeutet, dass dieses Modell einen Thread pro Clientanfrage erstellt. Wenn mehr Clientanfragen Blocking-IO-Operationen erfordern, sind fast alle Threads mit der Vorbereitung ihrer Antworten beschäftigt. Dann müssen die verbleibenden Clientanfragen länger warten.
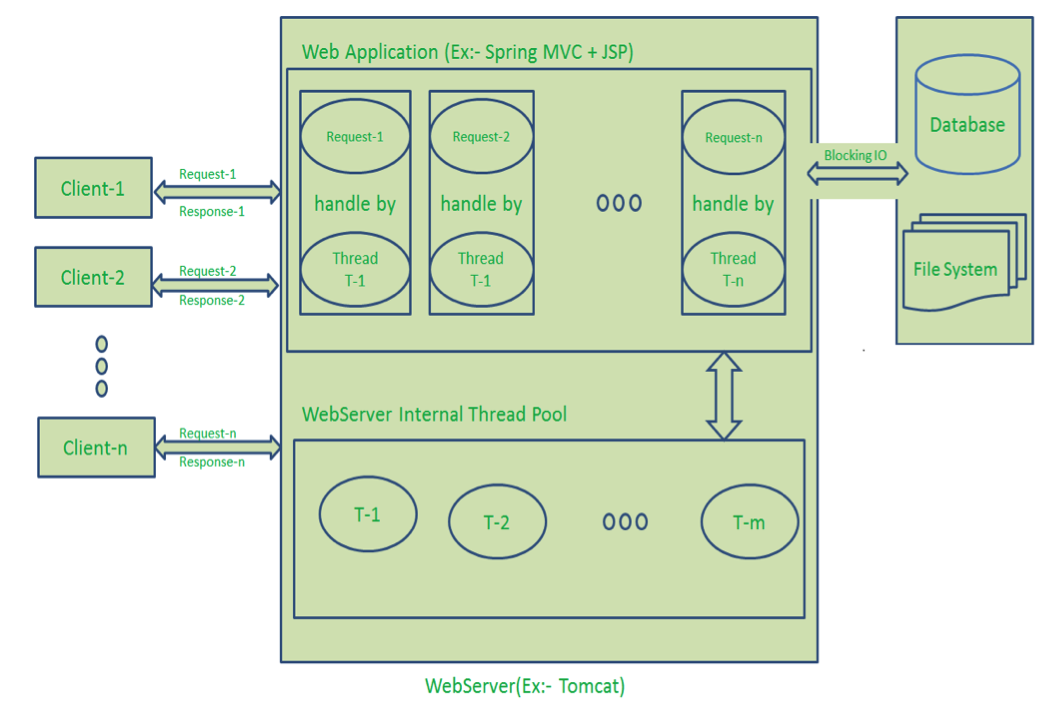
Diagrammbeschreibung:
- Hier senden „n“ Anzahl von Clients Anfragen an den Webserver. Nehmen wir an, sie greifen gleichzeitig auf unsere Webanwendung zu.
- Wir nehmen an, unsere Clients sind Client-1, Client-2… und Client-n.
- Der Webserver verwaltet intern einen begrenzten Thread-Pool. Nehmen wir an, „m“ Anzahl von Threads im Thread-Pool.
- Der Webserver empfängt diese Anfragen nacheinander.
- Der Webserver nimmt Client-1 Anfrage-1, nimmt einen Thread T-1 aus dem Thread-Pool und weist diese Anfrage Thread T-1 zu.
- Thread T-1 liest und verarbeitet Client-1 Anfrage-1. Client-1 Anfrage-1 erfordert keine Blocking-IO-Operationen. Thread T-1 führt die notwendigen Schritte durch und bereitet Antwort-1 vor und sendet sie zurück an den Server. Der Webserver sendet wiederum diese Antwort-1 an den Client-1.
- Der Webserver nimmt eine weitere Client-2 Anfrage-2, nimmt einen Thread T-2 aus dem Thread-Pool und weist diese Anfrage Thread T-2 zu.
- Thread T-2 liest und verarbeitet Client-2 Anfrage-2. Client-2 Anfrage-2 erfordert keine Blocking-IO-Operationen. Thread T-2 führt die notwendigen Schritte durch und bereitet Antwort-2 vor und sendet sie zurück an den Server. Der Webserver sendet wiederum diese Antwort-2 an den Client-2.
- Der Webserver nimmt eine weitere Client-n Anfrage-n, nimmt einen Thread T-n aus dem Thread-Pool und weist diese Anfrage Thread T-n zu.
- Thread T-n liest und verarbeitet Client-n Anfrage-n. Client-n Anfrage-n erfordert schwere Blocking-IO- und Rechenoperationen. Thread T-n benötigt mehr Zeit, um mit externen Systemen zu interagieren, führt die notwendigen Schritte durch und bereitet Antwort-n vor und sendet sie zurück an den Server. Der Webserver sendet wiederum diese Antwort-n an den Client-n.
- Wenn „n“ größer als „m“ ist (meistens ist das der Fall), weist der Server Threads den Clientanfragen bis zu den verfügbaren Threads zu. Nachdem alle m Threads genutzt wurden, müssen die verbleibenden Clientanfragen in der Warteschlange warten, bis einige der beschäftigten Threads ihren Anfrageverarbeitungsjob beenden und frei sind, um die nächste Anfrage aufzunehmen. Wenn diese Threads mit Blocking-IO-Aufgaben (zum Beispiel Interaktion mit Datenbanken, Dateisystemen, JMS-Warteschlangen, externen Diensten usw.) für längere Zeit beschäftigt sind, müssen die verbleibenden Clients länger warten.
- Sobald Threads im Thread-Pool frei und für die nächsten Aufgaben verfügbar sind, nimmt der Server diese Threads auf und weist sie den verbleibenden Clientanfragen zu.
- Jeder Thread nutzt viele Ressourcen wie Speicher usw. Also, bevor diese Threads vom beschäftigten Zustand in den Wartezustand übergehen, sollten sie alle erworbenen Ressourcen freigeben.
Nachteile des Request/Response zustandslosen Modells:
- Die Handhabung von immer mehr gleichzeitigen Clientanfragen ist etwas schwierig.
- Wenn die gleichzeitigen Clientanfragen zunehmen, dann muss es mehr und mehr Threads nutzen, die letztendlich mehr Speicher verbrauchen.
- Manchmal müssen Clientanfragen auf verfügbare Threads warten, um ihre Anfragen zu verarbeiten.
- Verschwendung von Zeit bei der Verarbeitung von Blocking-IO-Aufgaben.
Node JS Architektur – Single Threaded Event Loop
Die Node JS Plattform folgt nicht dem Request/Response Multi-Threaded zustandslosen Modell. Sie folgt einem Single Threaded mit Event Loop Modell. Das Verarbeitungsmodell von Node JS basiert hauptsächlich auf dem Javascript Event-basierten Modell mit Javascript Callback-Mechanismus. Man sollte ein gutes Wissen darüber haben, wie Javascript Events und der Callback-Mechanismus funktionieren. Wenn Sie dies nicht wissen, lesen Sie bitte zuerst diese Beiträge oder Tutorials, um eine Vorstellung zu bekommen, bevor Sie zum nächsten Schritt in diesem Beitrag übergehen. Da Node JS dieser Architektur folgt, kann es sehr einfach immer mehr gleichzeitige Clientanfragen handhaben. Bevor wir die Interna dieses Modells besprechen, schauen wir uns zuerst das Diagramm unten an. Ich habe versucht, dieses Diagramm zu entwerfen, um jeden Punkt der Node JS Interna zu erklären. Das Herzstück des Verarbeitungsmodells von Node JS ist der „Event Loop“. Wenn wir dies verstehen, dann ist es sehr einfach, die Interna von Node JS zu verstehen. Verarbeitungsschritte des Single Threaded Event Loop Modells:
- Clients senden Anfragen an den Webserver.
- Der Node JS Webserver verwaltet intern einen begrenzten Thread-Pool, um Dienste für die Clientanfragen zu bieten.
- Der Node JS Webserver empfängt diese Anfragen und platziert sie in eine Warteschlange. Sie ist bekannt als „Event Queue“.
- Der Node JS Webserver hat intern eine Komponente, bekannt als „Event Loop“. Warum er diesen Namen hat, liegt daran, dass er eine unbestimmte Schleife verwendet, um Anfragen zu empfangen und zu verarbeiten.
- Event Loop verwendet nur einen einzigen Thread. Es ist das Herzstück des Verarbeitungsmodells der Node JS Plattform.
- Event Loop prüft, ob eine Clientanfrage in der Event Queue platziert ist. Wenn nein, dann wartet er unbestimmt auf eingehende Anfragen.
- Wenn ja, dann nimmt er eine Clientanfrage aus der Event Queue auf.
- Beginnt mit der Verarbeitung dieser Clientanfrage.
- Wenn diese Clientanfrage keine Blocking-IO-Operationen erfordert, dann verarbeitet er alles, bereitet eine Antwort vor und sendet sie zurück an den Client.
- Wenn diese Clientanfrage einige Blocking-IO-Operationen wie die Interaktion mit Datenbanken, Dateisystemen, externen Diensten erfordert, dann folgt er einem anderen Ansatz.
- Überprüft die Verfügbarkeit von Threads aus dem internen Thread-Pool.
- Nimmt einen Thread auf und weist diese Clientanfrage diesem Thread zu.
- Dieser Thread ist verantwortlich dafür, diese Anfrage zu übernehmen, zu verarbeiten, Blocking-IO-Operationen durchzuführen, eine Antwort vorzubereiten und sie zurück an den Event Loop zu senden.
- Event Loop sendet diese Antwort wiederum an den entsprechenden Client.
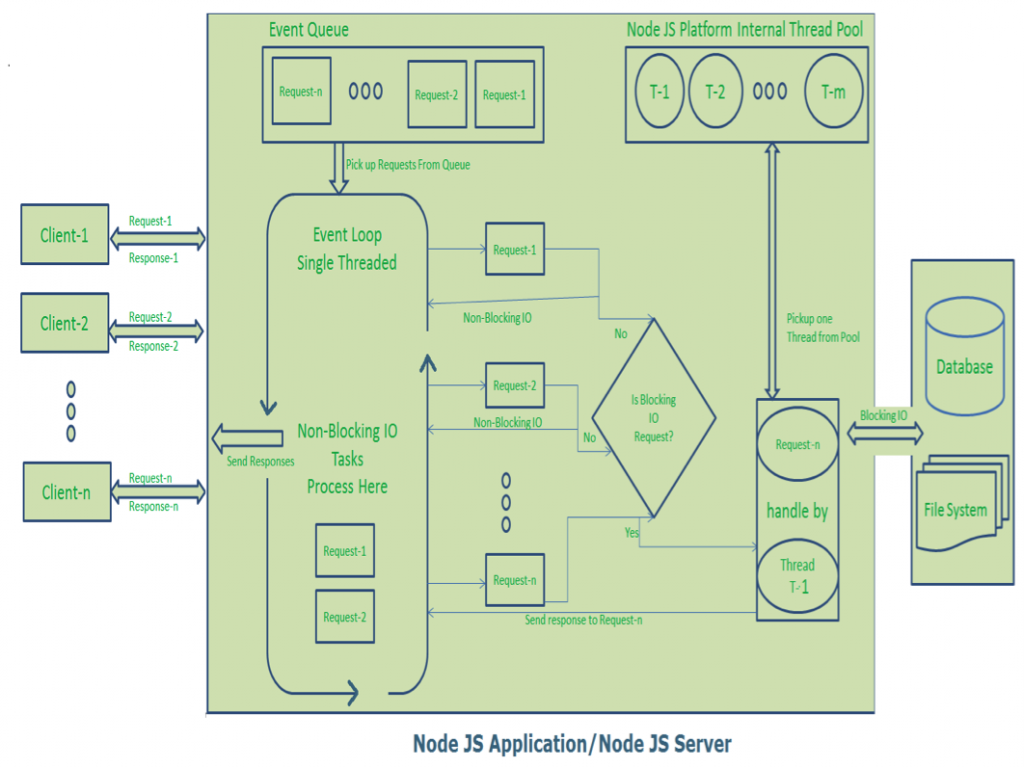
Beschreibung des Diagramms:
- Hier senden „n“ Anzahl von Clients Anfragen an den Webserver. Wir gehen davon aus, dass sie gleichzeitig auf unsere Webanwendung zugreifen.
- Wir nehmen an, unsere Clients sind Client-1, Client-2 … und Client-n.
- Der Webserver verwaltet intern einen begrenzten Thread-Pool. Wir nehmen an, „m“ Anzahl von Threads im Thread-Pool.
- Der Node JS Webserver empfängt Client-1, Client-2 … und Client-n Anfragen und platziert sie in der Event Queue.
- Der Node JS Event Loop nimmt diese Anfragen nacheinander auf.
- Event Loop nimmt Client-1 Anfrage-1 auf
- Überprüft, ob Client-1 Anfrage-1 irgendwelche Blocking-IO-Operationen erfordert oder mehr Zeit für komplexe Berechnungsaufgaben benötigt.
- Da diese Anfrage eine einfache Berechnung und eine Non-Blocking-IO-Aufgabe ist, benötigt sie keinen separaten Thread zur Verarbeitung.
- Event Loop verarbeitet alle in dieser Client-1 Anfrage-1 bereitgestellten Schritte (hier bedeutet Operationen Java Script’s Funktionen) und bereitet Antwort-1 vor.
- Event Loop sendet Antwort-1 an Client-1.
- Event Loop nimmt Client-2 Anfrage-2 auf
- Überprüft, ob Client-2 Anfrage-2 irgendwelche Blocking-IO-Operationen erfordert oder mehr Zeit für komplexe Berechnungsaufgaben benötigt.
- Da diese Anfrage eine einfache Berechnung und eine Non-Blocking-IO-Aufgabe ist, benötigt sie keinen separaten Thread zur Verarbeitung.
- Event Loop verarbeitet alle in dieser Client-2 Anfrage-2 bereitgestellten Schritte und bereitet Antwort-2 vor.
- Event Loop sendet Antwort-2 an Client-2.
- Event Loop nimmt Client-n Anfrage-n auf
- Überprüft, ob Client-n Anfrage-n irgendwelche Blocking-IO-Operationen erfordert oder mehr Zeit für komplexe Berechnungsaufgaben benötigt.
- Da diese Anfrage eine sehr komplexe Berechnungs- oder Blocking-IO-Aufgabe ist, verarbeitet Event Loop diese Anfrage nicht.
- Event Loop nimmt Thread T-1 aus dem internen Thread-Pool auf und weist diese Client-n Anfrage-n Thread T-1 zu.
- Thread T-1 liest und verarbeitet Anfrage-n, führt die notwendigen Blocking-IO- oder Berechnungsaufgaben durch und bereitet schließlich Antwort-n vor.
- Thread T-1 sendet diese Antwort-n zurück an den Event Loop.
- Event Loop sendet diese Antwort-n wiederum an Client-n.
Hier ist die Clientanfrage ein Aufruf einer oder mehrerer Java Script Funktionen. Java Script Funktionen können andere Funktionen aufrufen oder ihre Callback-Funktionsnatur nutzen. So sieht jede Clientanfrage wie folgt aus:
function(other-functioncall, callback-function)
Zum Beispiel:
function1(function2,callback1);
function2(function3,callback2);
function3(input-params);
ANMERKUNG:
Wenn Sie nicht verstehen, wie diese Funktionen ausgeführt werden, dann denke ich, dass Sie nicht mit Java Script Funktionen und dem Callback-Mechanismus vertraut sind.
Wir sollten eine Vorstellung von Java Script Funktionen und Callback-Mechanismen haben. Bitte gehen Sie einige Online-Tutorials durch, bevor Sie mit der Entwicklung unserer Node JS Anwendung beginnen.
Vorteile der Node JS Architektur – Single Threaded Event Loop
Die Handhabung von immer mehr gleichzeitigen Clientanfragen ist sehr einfach.
Auch wenn unsere Node JS Anwendung immer mehr gleichzeitige Clientanfragen erhält, besteht keine Notwendigkeit, mehr und mehr Threads zu erstellen, wegen des Event Loops.
Die Node JS Anwendung verwendet weniger Threads, sodass sie nur weniger Ressourcen oder Speicher benötigt.
Event Loop Pseudo-Code
Als Java-Entwickler werde ich versuchen, „Wie der Event Loop funktioniert“ in Java-Terminologie zu erklären. Es ist nicht in reinem Java-Code, ich denke, jeder kann das verstehen. Wenn Sie Probleme haben, dies zu verstehen, hinterlassen Sie bitte einen Kommentar.
public class EventLoop {
while(true){
if(Event Queue receives a JavaScript Function Call){
ClientRequest request = EventQueue.getClientRequest();
If(request requires BlokingIO or takes more computation time)
Assign request to Thread T1
Else
Process and Prepare response
}
}
}
Das ist alles für die Node JS Architektur und die Node JS Single Threaded Event Loop. Node JS Architecture – Leitfaden
