
Fooocus: Die neueste Stable Diffusion Anwendung
In den letzten Wochen haben wir einen sprunghaften Anstieg der Popularität der neuesten Stable Diffusion Anwendung Fooocus erlebt. Fooocus ist eine Bildgenerierungssoftware, die auf Gradio basiert und von dem renommierten Open-Source-Entwickler Illyasviel entwickelt wurde, der auch für das bekannte ControlNet verantwortlich ist. Dieses Tool bietet einen neuen Ansatz für die Bildsynthese-Pipeline und stellt eine Alternative zu etablierten Frameworks wie AUTOMATIC1111’s Stable Diffusion Web UI und MidJourney dar.
Einführung
In diesem Artikel beginnen wir mit einem Überblick über die Funktionen und Möglichkeiten dieser neuen Plattform. Wir möchten die Unterschiede und Verbesserungen hervorheben, die Fooocus im Vergleich zu anderen Tools bietet, die wir bereits in unserem Blog behandelt haben. Darüber hinaus erläutern wir, warum Fooocus in Ihr Bildsynthese-Toolkit aufgenommen werden sollte. Anschließend demonstrieren wir die Einrichtung und erklären, wie Sie mit der Bilderzeugung beginnen. Am Ende dieses Leitfadens haben Sie ein umfassendes Verständnis der verschiedenen nützlichen Einstellungen und integrierten Funktionen von Fooocus.
Voraussetzungen
- GPU-Anforderungen: Eine leistungsstarke GPU ist unerlässlich (NVIDIA empfohlen) für eine schnellere Verarbeitung. Eine Mindestanforderung von 8 GB VRAM wird für optimale Leistung empfohlen.
- Vortrainierte Modelle: Laden Sie die erforderlichen vortrainierten Modelle herunter (z. B. Stable Diffusion Varianten), die Ihrem bevorzugten Kunststil oder Anwendungsbereich entsprechen.
- Prompt-Optimierung: Entwickeln Sie die Fähigkeit, detaillierte und beschreibende Prompts zu erstellen, um das Modell gezielt zu steuern.
- Optionale KI-Upscaling: Verwenden Sie KI-gestützte Upscaling-Tools wie ESRGAN, um die endgültige Bildqualität zu verbessern.
Was bietet Fooocus für Stable Diffusion Nutzer?
Eines der Hauptmerkmale von Fooocus ist die Vereinfachung vieler komplexer Einstellungen, die normalerweise erforderlich sind, um hochwertige Bilder zu generieren. Diese Verbesserungen sind in der technischen Dokumentation auf GitHub beschrieben, aber hier sind einige der wichtigsten Funktionen:
- Stil: Das Fooocus V2 Stilsystem ermöglicht eine MidJourney-ähnliche Prompterweiterung durch GPT-2 mit minimalen Rechenkosten. Dadurch können Benutzer einfache Eingaben verwenden, um vielschichtige und komplexe Bilder zu erzeugen.
- Integrierter Refining-Wechsel: Innerhalb eines einzelnen K-Samplers wird eine nahtlose Übertragung der Parameter des Basismodells auf den Refiner ermöglicht. Diese Technik wird auch in der AUTOMATIC1111 Web UI verwendet.
- Negative Bildaspektverhältnis (ADM) Führung: Die höchsten Auflösungen von Stable Diffusion XL haben keine Cross-Attention. Fooocus kompensiert dies, indem positive und negative Signale angepasst werden, um den Mangel an classifier-free guidance auszugleichen.
- Self-Attention Guidance: Basierend auf Forschungsergebnissen hat das Fooocus-Team eine subtile Form der Self-Attention Guidance integriert. Zusammen mit der negativen ADM-Führung hilft dies, einen häufig berichteten Weichzeichnungseffekt in SD XL-Bildern zu minimieren.
- Automatische LoRA-Modellanwendung: Fooocus integriert automatisch das Modell „sd_xl_offset_example-lora_1.0.safetensors“ mit einer Stärke von 0,1. Tests haben gezeigt, dass Werte unter 0,5 durchweg bessere Ergebnisse liefern als eine komplette Deaktivierung.
- Optimierte Sampler-Parameter: Die Entwickler haben die Sampler-Parameter sorgfältig angepasst und optimiert.
- Auflösungsanpassungen: Eine feste Auflösungseinstellung basierend auf den optimalen Seitenverhältnissen für die Bildsynthese mit SD XL.
Diese Funktionen reduzieren den technischen Aufwand erheblich, um die Software effizient nutzen zu können. Nun, da wir die wichtigsten Vorteile von Fooocus behandelt haben, gehen wir zur Einrichtung der Benutzeroberfläche über, bevor wir Vor- und Nachteile bewerten.
Fooocus Demo
Einrichtung
Um die Fooocus-Demo auszuführen, müssen wir zunächst Conda installieren.
Öffnen Sie das Terminal und führen Sie folgende Befehle aus:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash Miniconda3-latest-Linux-x86_64.sh
Befolgen Sie die Anweisungen im Terminal und bestätigen Sie mit „Ja“, wenn Sie dazu aufgefordert werden. Nach Abschluss der Installation schließen Sie das Terminal und öffnen es erneut.
Nun richten wir die benötigte Umgebung ein:
conda env create -f environment.yaml conda activate fooocus pip install -r requirements_versions.txt
Diese Befehle installieren alle erforderlichen Abhängigkeiten für Fooocus. Beim ersten Start lädt Fooocus automatisch ein Stable Diffusion XL Modell von HuggingFace herunter.
Um Fooocus zu starten, führen Sie den folgenden Befehl aus:
python entry_with_update.py --listen --share
Fooocus Anwendung nutzen
Nun können wir mit der Bildsynthese beginnen. Fooocus arbeitet ähnlich wie Stable Diffusion oder MidJourney, bietet aber einige wesentliche Unterschiede.
Der erste Schritt besteht darin, eine schnelle Testgenerierung mit den Standardoptionen durchzuführen. Geben Sie einfach ein Prompt ein und klicken Sie auf „Generate“. Fooocus verwendet standardmäßig das Modell „juggernautXL_version6Rundiffusion.safetensors“, das eine Vielzahl realistischer und künstlerischer Stile unterstützt.
Die Standardeinstellungen generieren zwei Bilder mit einer Auflösung von 1152×896 (9:7 Seitenverhältnis). Während des Diffusionsprozesses können wir die Bildentwicklung in Echtzeit verfolgen.
Bildgenerierung mit Fooocus
Die Fooocus-Web-Benutzeroberfläche ermöglicht es uns, eine Beispielgenerierung mit der Grundeingabe zu betrachten. Die Standardeinstellungen erzeugen zwei Bilder mit einer Auflösung von 1152×896 (9:7 Seitenverhältnis), und wir können den Diffusionsprozess in Echtzeit beobachten.

Von hier aus können wir verschiedene erweiterte Einstellungen in Fooocus erkunden, indem wir auf den Umschalter unten auf dem Bildschirm klicken. Die erweiterten Einstellungen werden dann auf der rechten Seite in organisierten Gradio-Tabs angezeigt.
Leistungseinstellungen
Der erste und vielleicht wichtigste Tab ist “Einstellungen”. Hier sehen wir einen der Hauptunterschiede zu einer typischen Pipeline: die Leistungseinstellungen. Diese sind vorkonfiguriert und optimiert, um eine unterschiedliche Anzahl von Diffusionsschritten auszuführen, um Bilder mit unterschiedlichen Qualitätsstufen und Geschwindigkeiten zu erzeugen:
- Geschwindigkeit: 30 Schritte
- Qualität: 60 Schritte
- Extreme Geschwindigkeit: 8 Schritte
Obwohl Fooocus anscheinend andere K-Sampler unterstützt, scheint es hart auf die Verwendung von “dpmpp_2m_sde_gpu” für alle Leistungseinstellungen voreingestellt zu sein.
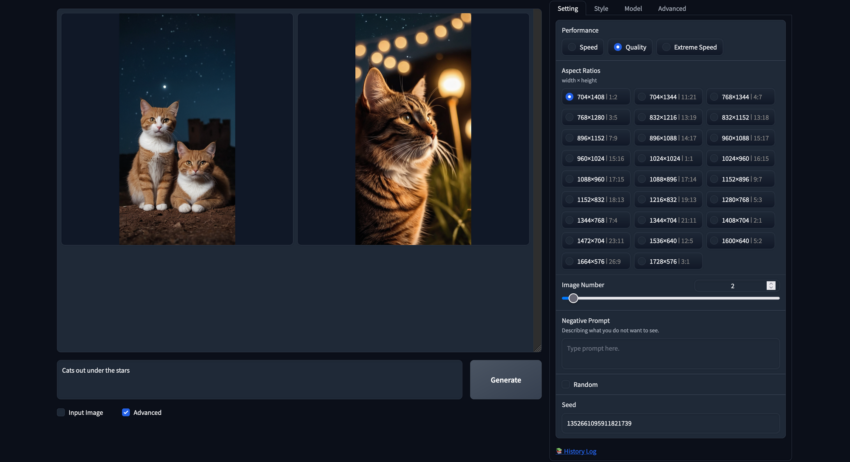
Auflösungen
Diese sind speziell optimierte Auflösungen für Stable Diffusion XL-Modelle. Diese Einschränkung der Bildgröße verbessert die Ausgabequalität erheblich, da Bilder, die mit nicht optimalen Auflösungen generiert werden, eher verzerrt erscheinen. Unten ist ein Beispiel für ein Bild, das mit einer Auflösung von 704×1408 generiert wurde.
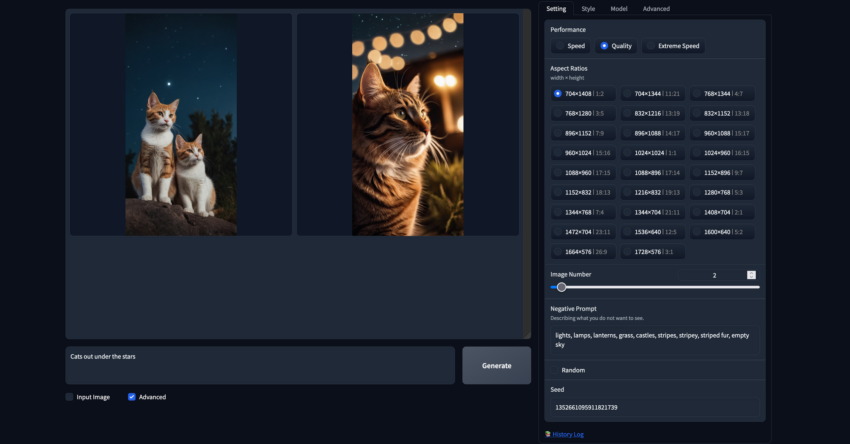
Negative Prompts
Die negative Eingabeaufforderung funktioniert als eine Art Gegenteil der regulären Eingabeaufforderung. Jegliche Begriffe, die darin enthalten sind, werden vom Modell so weit wie möglich unterdrückt. Negative Prompts können verwendet werden, um unerwünschte Merkmale aus generierten Bildern zu entfernen oder einige der bekannten Probleme von Stable Diffusion mit bestimmten Objekten zu minimieren. Im unten gezeigten Beispiel haben wir denselben Seed wie bei der vorherigen Generierung verwendet, aber eine zusätzliche negative Eingabeaufforderung hinzugefügt, um die Ausgabe zu verändern.
Sie können den Seed manuell zuweisen, indem Sie das Kontrollkästchen “Zufällig” unter dem Feld für die negative Eingabeaufforderung deaktivieren und einen Wert eingeben.
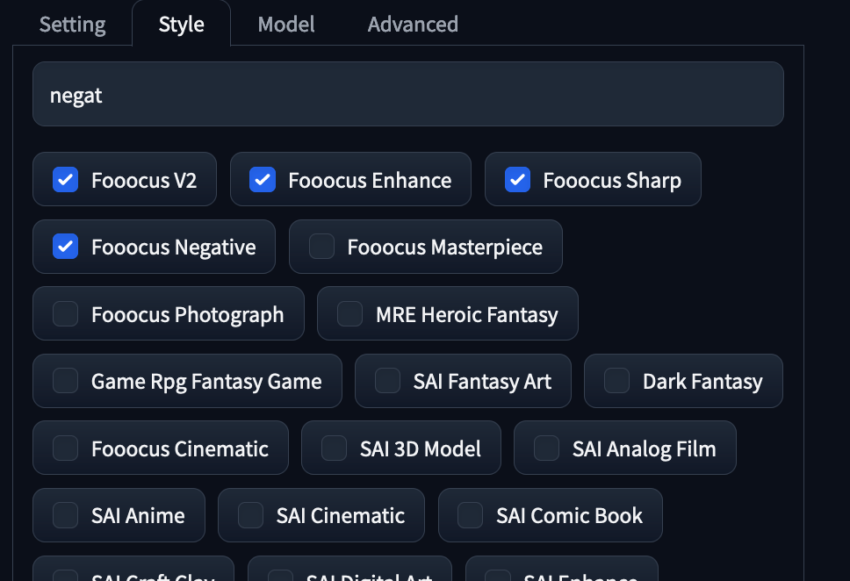
Stiloptionen
Der nächste Tab, “Stil”, enthält GPT-2-Verbesserungen, die Eingabeaufforderungen für dynamischere Ergebnisse erweitern. Probieren Sie verschiedene Stile aus, um deren Auswirkungen auf die endgültigen Ergebnisse zu sehen. Wir empfehlen besonders die Verwendung der voreingestellten Stile für alle Generierungen.
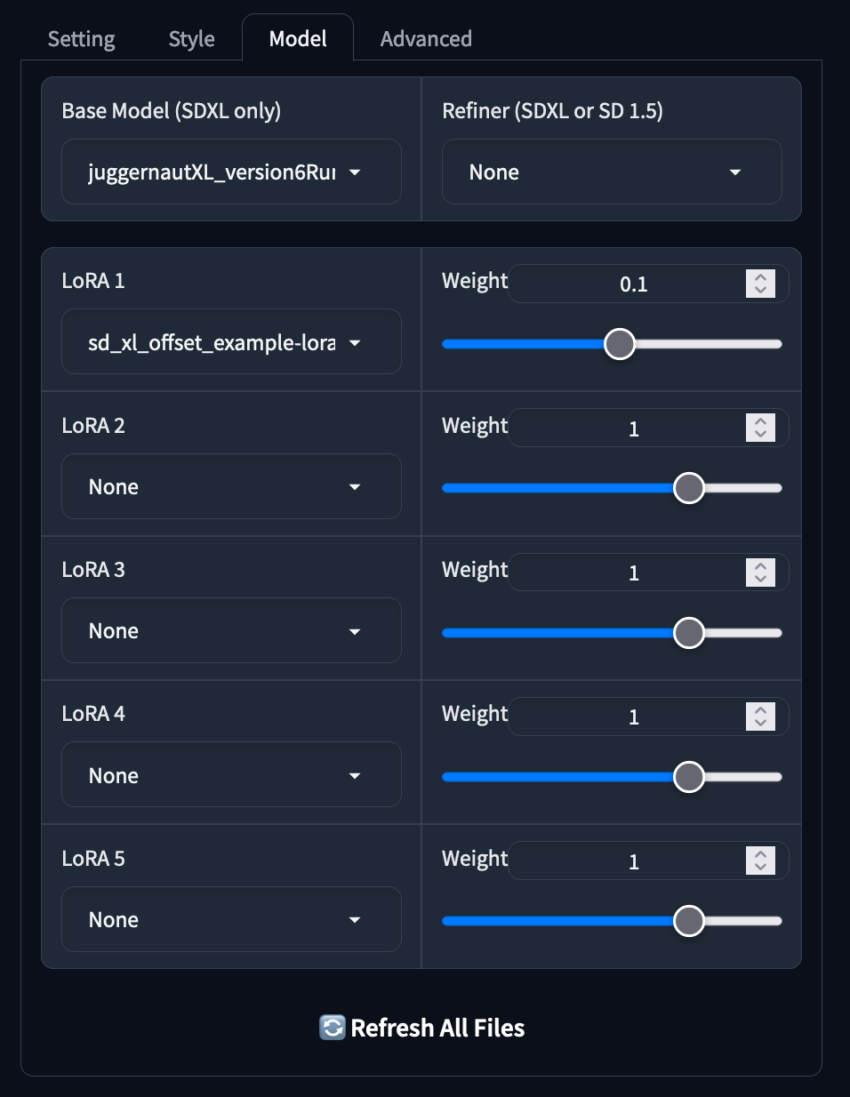
Modelleinstellungen
Der nächste Tab, “Modell”, ist wohl der wichtigste, da er es ermöglicht, zwischen dem Haupt-Checkpoint und LoRAs (Low-Rank Adaptations) zu wechseln. Intuitive Schieberegler ermöglichen es uns, das Gewicht zusätzlicher Modelle einfach anzupassen, wodurch es wesentlich einfacher wird, die Merkmale zweier LoRAs zu kombinieren.
Die Anwendung wird auch automatisch “sd_xl_offset_example-lora” mit einem Gewicht von 0,1 herunterladen und zuweisen, das wir entfernen können, falls gewünscht. Falls wir ein Modell während einer aktiven Sitzung herunterladen, aktualisiert die Schaltfläche “Alle Dateien aktualisieren” am unteren Rand die Liste der verfügbaren Modelle.
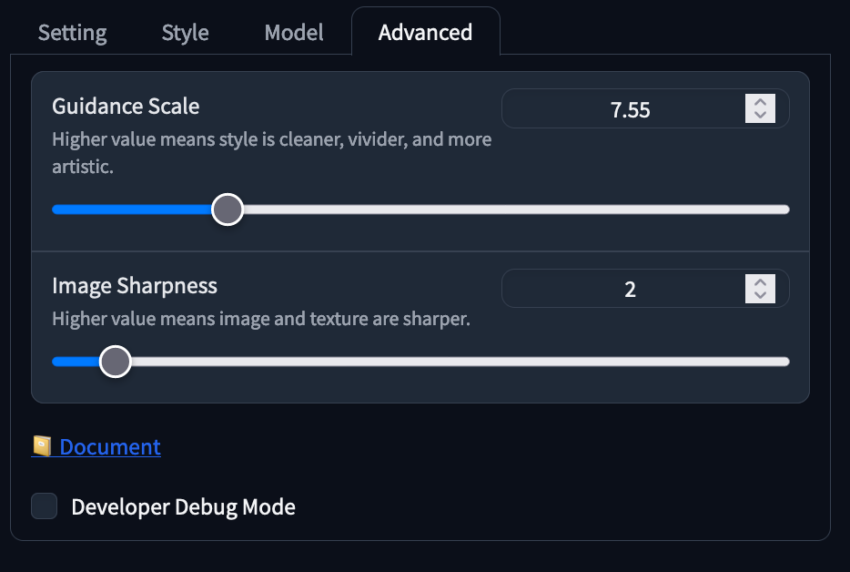
Erweiterte Einstellungen
Der letzte Tab, “Erweitert”, enthält die Schieberegler für Leitfaden-Skala und Bildschärfe:
- Leitfaden-Skala: Steuert, wie stark die Eingabeaufforderung das endgültige Bild beeinflusst. Der optimale Bereich liegt zwischen 4-10.
- Bildschärfe: Erhöht die Schärfe des Bildes, kann aber einen unnatürlichen Effekt hervorrufen, wenn sie zu hoch eingestellt wird.
Bild-zu-Bild-Generierung mit Fooocus
Zusätzlich zur Umschaltfunktion für erweiterte Optionen gibt es eine Umschaltfunktion für Eingabebilder direkt daneben. Damit können wir Bild-zu-Bild-Generierung in Fooocus durchführen. Illyasviel, der Entwickler dieses Projekts, ist auch der Schöpfer des beliebten ControlNet. Sie haben Bild-zu-Bild mit einem robusten ControlNet-System kombiniert, um Eingabebilder automatisch zur Steuerung der Generierung zu verwenden.
Fooocus bietet drei Hauptmodi zur Bildbearbeitung, die es ermöglichen, generierte Bilder gezielt anzupassen und zu verbessern.
Upscaling oder Variation
Fooocus stellt fünf verschiedene Einstellungen für Variationen und Hochskalierungen zur Verfügung:
- Vary (subtil): Führt leichte Änderungen am Bild durch.
- Vary (stark): Führt größere Veränderungen durch, wodurch sich das Bild deutlicher vom Original unterscheidet.
- Upscale (1.5x): Erhöht die Auflösung des Bildes um das 1,5-fache.
- Upscale (2x): Verdoppelt die Auflösung des Bildes.
- Upscale (fast 2x): Schnelles Hochskalieren mit einer Verdopplung der Auflösung.
Die ersten beiden Optionen ermöglichen es, entweder sanfte oder deutlichere Variationen eines Bildes zu erzeugen, während die Hochskalierungsoptionen dazu dienen, die Bildauflösung zu verbessern und feinere Details herauszuarbeiten.
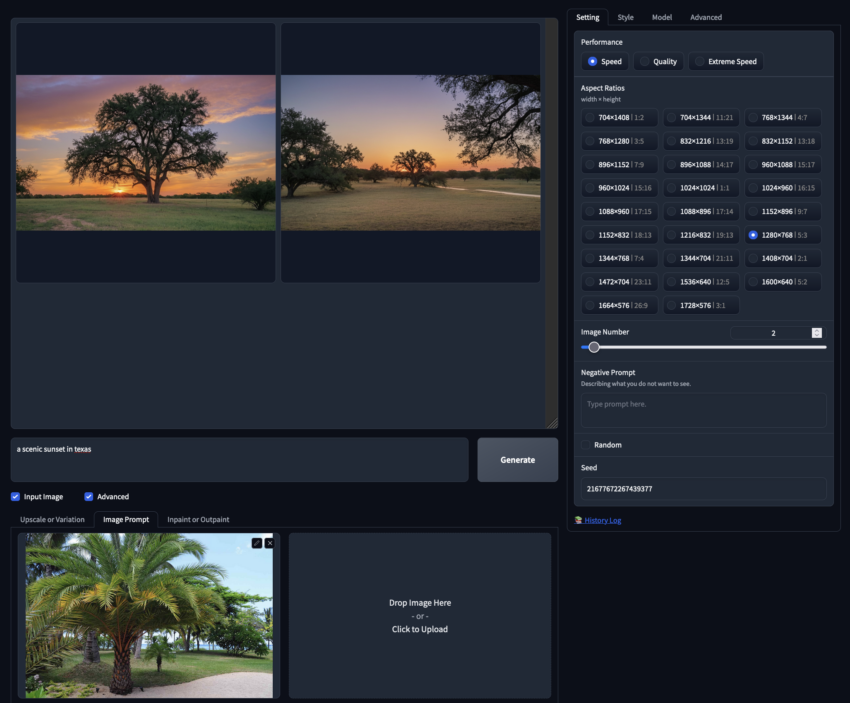
Bild-Prompting
Diese Funktion ähnelt der traditionellen Bild-zu-Bild-Verarbeitung in Stable Diffusion, geht jedoch noch einen Schritt weiter, indem sie die Nutzung mehrerer Eingabebilder anstelle eines einzigen ermöglicht. Durch die Kombination verschiedener Bildreferenzen lassen sich abwechslungsreichere und differenziertere Ergebnisse generieren.
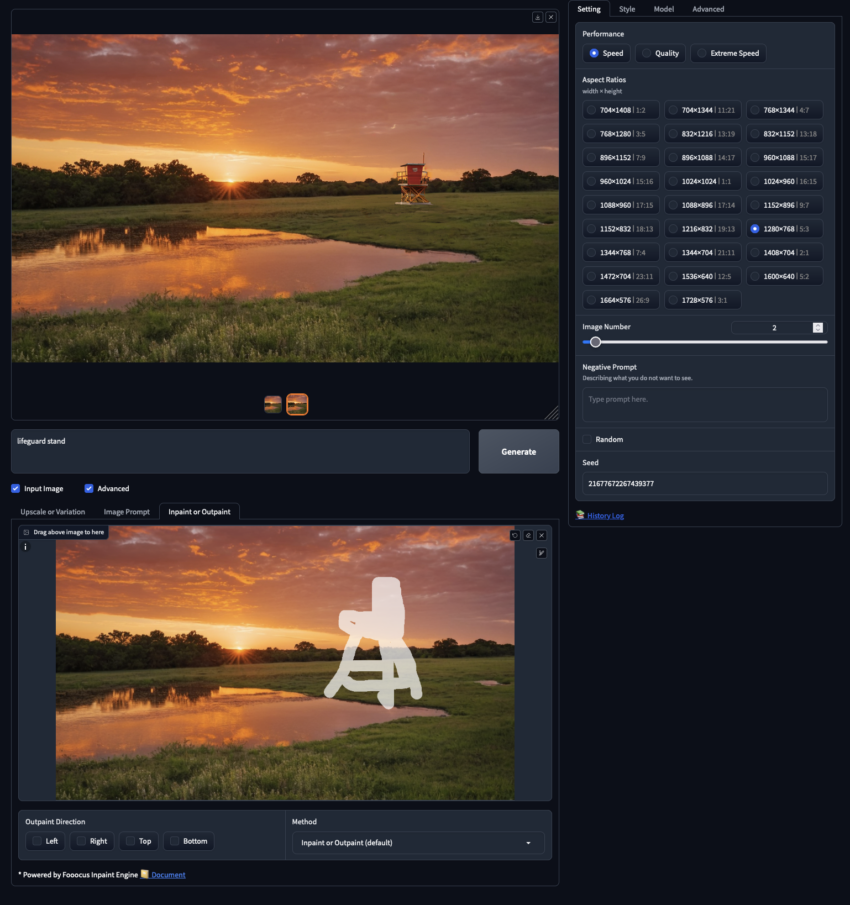
Inpainting und Outpainting
Inpainting: Erlaubt es den Nutzern, bestimmte Bereiche eines Bildes gezielt zu modifizieren oder fehlende Details in einem maskierten Bereich hinzuzufügen.
Outpainting: Erweiterung des Bildes über seine ursprünglichen Grenzen hinaus, indem die KI vorhersagt, welche Elemente sich außerhalb des aktuellen Bildausschnitts befinden könnten.
Diese Werkzeuge ermöglichen es Nutzern, neue Elemente in Bilder einzufügen, beispielsweise einen Rettungsturm an einem Strand hinzuzufügen. Durch die Kombination aller drei Methoden lassen sich äußerst kreative und detailreiche Ergebnisse erzielen.
Fazit
Fooocus bietet eine breite Palette leistungsstarker Funktionen für die KI-gestützte Bildgenerierung – von grundlegenden Prompts über fortgeschrittene Modellkombinationen bis hin zur Bild-zu-Bild-Verarbeitung. Durch die Integration von Stable Diffusion XL, ControlNet und LoRAs schafft Fooocus eine optimierte Umgebung für hochqualitative Bildsynthese.
Das Experimentieren mit verschiedenen Einstellungen, Stilen und Modellen eröffnet unzählige Möglichkeiten für die individuelle Bildgestaltung. Fooocus zeichnet sich dabei besonders durch seine einfache Bedienbarkeit und automatische Optimierungen aus, wodurch es sowohl für Anfänger als auch für erfahrene Nutzer ideal geeignet ist.
