
Einführung in NVIDIA CUDA für Paralleles Computing
In diesem Artikel stellen wir NVIDIA CUDA für paralleles Computing vor. CUDA (Compute Unified Device Architecture) ist die Plattform von NVIDIA für paralleles Computing – die Software-Schicht, die es Entwicklern ermöglicht, die Leistung von GPUs für allgemeine Aufgaben zu nutzen.
CUDA dient als Verbindung zwischen NVIDIA-GPUs und GPU-basierten Anwendungen und ermöglicht die Nutzung beliebter Deep-Learning-Bibliotheken wie TensorFlow und PyTorch zur Beschleunigung von GPU-gestützten Berechnungen. Diese Fähigkeit ist entscheidend für die Optimierung von Deep-Learning-Aufgaben oder für den Betrieb GPU-beschleunigter Anwendungen.
Voraussetzungen
- Verständnis für paralleles Computing: Grundlegende Konzepte wie Threads, Parallelität und Aufgabenverteilung kennen.
- Grundlegendes Wissen über GPUs: Verstehen, was GPUs sind und welche allgemeine Rolle sie in der Informatik spielen.
- Grundlagen der linearen Algebra: Vertrautheit mit Matrizen- und Vektoroperationen, da CUDA häufig Matrixberechnungen umfasst.
- Installiertes CUDA-Toolkit: Stellen Sie sicher, dass das CUDA-Toolkit und die kompatiblen NVIDIA-GPU-Treiber auf Ihrem System installiert sind.
Eine kurze Geschichte von NVIDIA CUDA
Compute Unified Device Architecture, kurz CUDA, ist eine parallele Computing-Plattform, die von NVIDIA entwickelt wurde und erstmals am 23. Juni 2007 veröffentlicht wurde. NVIDIA CUDA hat die Nutzung von GPUs für allgemeine Berechnungen (GPGPU) revolutioniert.
CUDA begann als NVIDIAs Lösung, das Potenzial von Grafikprozessoren (GPUs) für allgemeine Berechnungen nutzbar zu machen. Vor CUDA wurden GPUs hauptsächlich für das Rendern von Grafiken in Spielen und visuellen Anwendungen verwendet. Allerdings erkannten Forscher, dass GPUs viele Berechnungen parallel ausführen können, wodurch sie auch für andere rechenintensive Aufgaben außerhalb der Grafikverarbeitung geeignet sind, wie wissenschaftliche Simulationen und Datenverarbeitung.
Ian Buck und die Entwicklung von CUDA
Ian Buck ist eine Schlüsselfigur in der Entwicklung von CUDA. Bevor er zu NVIDIA kam, arbeitete Ian Buck an der Programmiersprache Brook an der Stanford University – einem der ersten Werkzeuge, das allgemeine Berechnungen auf GPUs ermöglichte. Seine Forschung und Erkenntnisse aus Brook legten den Grundstein für das, was später CUDA werden sollte.
Er trat NVIDIA in den frühen 2000er Jahren bei und spielte eine zentrale Rolle bei der Transformation von GPUs von grafikfokussierter Hardware zu leistungsstarken Werkzeugen für allgemeine Berechnungen (GPGPU). Buck leitete das Team, das CUDA bei NVIDIA entwickelte. Er arbeitete an der Schaffung einer Plattform, auf der Entwickler mit gängigen Programmiersprachen wie C auf die Rechenleistung von GPUs für nicht-grafische Aufgaben zugreifen konnten. Dies stellte einen bedeutenden Fortschritt gegenüber früheren, komplexeren Methoden der GPGPU-Programmierung, wie z. B. Shader-Sprachen, dar.
Im Jahr 2007 führten Bucks Bemühungen zur Veröffentlichung von CUDA, NVIDIAs revolutionärer Plattform für paralleles Computing. NVIDIA CUDA machte es möglich, GPUs für verschiedene Anwendungen zu nutzen, darunter wissenschaftliche Forschung, technische Simulationen und schließlich KI sowie Deep Learning. Bis etwa 2015 verlagerte sich die Entwicklung von CUDA zunehmend auf neuronale Netzwerke und Künstliche Intelligenz.
Warum brauchen wir CUDA?
Eine CPU (Central Processing Unit) ist die zentrale Komponente eines Computers, die für die Ausführung von Code verantwortlich ist. Sie übernimmt Aufgaben wie Dateiverwaltung, Datenverarbeitung und die Verarbeitung von Benutzereingaben. Während eine CPU Multitasking beherrscht, kann jeder Kern nur eine Aufgabe gleichzeitig ausführen. Typischerweise haben CPUs 2 bis 8 Kerne – mehr als ausreichend für alltägliche Aufgaben, da sie so schnell arbeiten, dass wir kaum bemerken, dass sie Aufgaben nacheinander abarbeiten.
Eine GPU (Graphics Processing Unit) hingegen ist auf parallele Berechnungen spezialisiert und daher leistungsstärker für Aufgaben wie Grafikrendering und zunehmend auch für Anwendungen in der Künstlichen Intelligenz und wissenschaftlichen Berechnungen. Während sowohl CPUs als auch GPUs essenzielle Hardwarekomponenten sind, sind sie für unterschiedliche Aufgaben optimiert.
Vergleich der Fähigkeiten von CPU und GPU
Betrachten wir die Zahlen: Eine leistungsstarke Verbraucher-CPU kann 16 Kerne haben, eine Nvidia RTX 4090 GPU verfügt über 16.384 CUDA-Kerne und eine H100 sogar über 18.432. Stellen Sie sich also vor, welche enorme Arbeitslast eine GPU bewältigen kann.
Die Rolle der CPU
Dann stellt sich die Frage: Warum brauchen wir überhaupt noch eine CPU?
Während GPUs für paralleles Rechnen und Multitasking bekannt sind, benötigen wir weiterhin CPUs, da sie besser für einfachere, sequentielle Aufgaben geeignet sind, bei denen Multitasking nicht immer effizient ist. Während GPUs viele kleinere Prozessoren besitzen, sind die wenigen, aber leistungsstarken Kerne einer CPU vorteilhaft für die sequentielle Ausführung von Aufgaben. Der eigentliche Vorteil ergibt sich jedoch aus der Kombination beider: CPUs übernehmen allgemeine Rechenaufgaben, während GPUs rechenintensive, parallele Workloads verarbeiten.
Die Rolle von CUDA
Hier kommt die Aufgabe für CUDA. CUDA ermöglicht es Entwicklern, effizient zwischen beiden Komponenten zu wechseln und die Leistung durch den besten Einsatz der jeweiligen Hardware zu maximieren.
CUDA erlaubt es Programmierern, die Leistung von Tausenden von GPU-Kernen zu nutzen, um parallele Algorithmen zu erstellen – entscheidend für Aufgaben wie maschinelles Lernen, Videobearbeitung, wissenschaftliche Forschung und Datenverarbeitung. Durch die Bereitstellung eines Programmiermodells und APIs ermöglicht CUDA Entwicklern, Code direkt auf der GPU auszuführen, wodurch die Leistung gegenüber herkömmlichen CPU-basierten Methoden erheblich gesteigert wird. Das Auslagern intensiver Workloads an die GPU über CUDA treibt Fortschritte im Bereich des Hochleistungsrechnens voran.
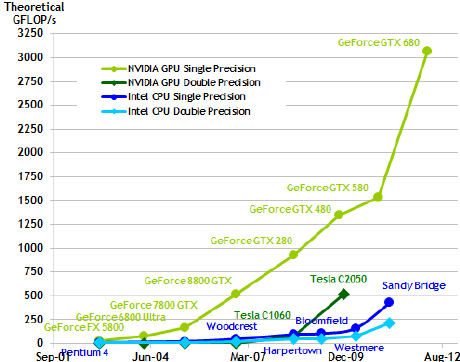
Diese Grafik zeigt, wie die Rechenleistung von NVIDIA- und Intel-Chips in den letzten zehn Jahren gewachsen ist, gemessen in Milliarden von Berechnungen pro Sekunde.
Verständnis der CUDA-Architektur
CUDA (Compute Unified Device Architecture) ist NVIDIAs Plattform für paralleles Computing. Sie ermöglicht es Entwicklern, die Leistung von GPUs für allgemeine Aufgaben zu nutzen – nicht nur für die Grafikwiedergabe.
Arten von CUDA-Funktionen
In CUDA werden drei Arten von Funktionen verwendet, um parallele Programmierung auf der CPU und GPU zu unterstützen, wobei jede eine spezifische Rolle hat. Hier ein Überblick:
1. Host-Funktionen (nur CPU)
Was sie tun: Dies sind reguläre Funktionen, die nur auf der CPU ausgeführt werden, nicht auf der GPU.
Wie sie funktionieren: Sie sind vergleichbar mit regulären C-Funktionen und verantwortlich für das Aufrufen und Verwalten von GPU-Operationen. Es sind keine speziellen Qualifikatoren erforderlich.
2. Kernel-Funktionen (CPU ruft auf, GPU führt aus)
Was sie tun: Kernel-Funktionen sind spezielle Funktionen, die auf der GPU ausgeführt, aber von der CPU aufgerufen werden.
Besonderheit: Beim Definieren dieser Funktionen muss der Qualifikator __global__ verwendet werden. Sie geben immer void zurück (d. h. keine Rückgabewerte).
Wie es funktioniert: Die CPU ruft diese Kernel-Funktionen auf, aber die tatsächliche Ausführung erfolgt auf der GPU. Beim Aufruf einer Kernel-Funktion muss angegeben werden, wie viele Threads und Blöcke für die parallele Verarbeitung genutzt werden sollen.
3. Device-Funktionen (nur GPU)
Was sie tun: Diese Funktionen werden auf der GPU ausgeführt und von ihr selbst aufgerufen. Sie helfen der GPU, Aufgaben effizienter zu erledigen, indem sie diese in kleinere Teile aufteilen.
Besonderheit: Diese Funktionen verwenden den Qualifikator __device__ und können im Gegensatz zu Kernel-Funktionen Werte beliebigen Typs zurückgeben (nicht nur void).
Zusammenfassung
- Host-Funktionen: Werden nur auf der CPU ausgeführt und dienen der Einrichtung und Verwaltung von GPU-Aufgaben.
- Kernel-Funktionen: Werden von der CPU aufgerufen, aber auf der GPU ausgeführt und übernehmen die rechenintensiven parallelen Berechnungen.
- Device-Funktionen: Werden von der GPU aufgerufen und ausgeführt und ermöglichen flexiblere Berechnungen direkt auf der GPU.
CUDA-Architektur
Die CUDA-Architektur ist darauf ausgelegt, die Rechenleistung der Grafikkarte maximal auszunutzen, indem Aufgaben in einer hierarchischen Struktur aus Grids, Blöcken und Threads organisiert werden. Jeder Block enthält mehrere Threads, und mehrere Blöcke bilden ein Grid. Diese Struktur ermöglicht ein hohes Maß an Parallelverarbeitung und eine effiziente Nutzung der GPU-Ressourcen.
Das Grid
Ein Grid in CUDA ist eine Gruppe von Threads, die denselben Kernel ausführen, jedoch nicht synchronisiert sind. Jeder CUDA-Aufruf von der CPU umfasst ein Grid. Während mehrere Grids gleichzeitig ausgeführt werden können, können Grids in Multi-GPU-Systemen nicht zwischen GPUs geteilt werden, da jede GPU ihre eigenen Grids für maximale Effizienz verwendet.
Der Block
Grids in CUDA bestehen aus Blöcken, die jeweils mehrere Threads und gemeinsam genutzten Speicher enthalten. Wie Grids werden auch Blöcke nicht zwischen Multiprozessoren geteilt. Alle Blöcke in einem Grid führen dasselbe Programm aus, und die Variable blockIdx hilft bei der Identifikation des aktuellen Blocks. Block-IDs können entweder eindimensional (1D) oder zweidimensional (2D) sein, abhängig von den Dimensionen des Grids. Typischerweise kann eine GPU bis zu 65.535 Blöcke enthalten.
Der Thread
Blöcke bestehen aus Threads, die auf den Kernen der Multiprozessoren ausgeführt werden. Im Gegensatz zu Grids und Blöcken sind Threads jedoch nicht auf einen einzigen Kern beschränkt. Jeder Thread hat eine eindeutige ID namens threadIdx, die je nach Dimension des Blocks 1D, 2D oder 3D sein kann. Die Thread-ID ist spezifisch für den Block, zu dem sie gehört. Threads haben zudem Zugriff auf eine bestimmte Menge an Registerspeicher, wobei typischerweise bis zu 512 Threads pro Block erlaubt sind. Diese Threads bilden die Grundlage für parallele Berechnungen auf einer GPU, ähnlich wie einzelne Arbeiter, die jeweils einen kleinen Teil einer Aufgabe übernehmen.
Diese Threads werden in Blöcke gruppiert, wobei jeder Block viele Threads enthalten kann (bis zu 1.024). Die GPU kann viele Blöcke parallel ausführen. Darüber hinaus besitzt jeder Thread eine eindeutige ID, die es ihm ermöglicht, an bestimmten Abschnitten einer Aufgabe zu arbeiten. Diese Struktur erlaubt es der GPU, eine Aufgabe in Tausende von Threads zu unterteilen und gleichzeitig auszuführen.
In der Regel führt eine größere Anzahl von Threads zu einer besseren Leistung.
Wichtige Komponenten der CUDA-Architektur
- Multiprozessoren: Die GPU verfügt über mehrere Streaming-Multiprozessoren (SMs), die jeweils viele CUDA-Kerne enthalten, welche die Threads ausführen.
- Kernel: Alle Threads führen dieselbe Funktion (Code) aus, die als Kernel bezeichnet wird.
- CUDA-Kerne: Dies sind die eigentlichen Prozessoren, die den Code ausführen. Je mehr, desto besser.
- Warp: Eine Gruppe von 32 Threads, die im SIMT-Modus (Single Instruction, Multiple Threads) gemeinsam ausgeführt werden. Dies ist die grundlegende Planungseinheit in CUDA.
In CUDA müssen die Teile eines Programms, die parallelisiert werden können, in viele Threads unterteilt werden, die gleichzeitig ausgeführt werden können. Diese Threads werden mit speziellen Funktionen, den sogenannten Kerneln, erstellt – einfach Funktionen, die auf der GPU ausgeführt werden. Der Kernel wird als Satz von Threads gestartet und ausgeführt.
Zusammenarbeit von CPU und GPU in CUDA
Im CUDA-Programmiermodell haben die CPU (Host) und die GPU (Device) jeweils ihren eigenen Speicher. Die CPU eignet sich hervorragend für serielle Aufgaben, stößt jedoch bei massiv parallelen Operationen an ihre Grenzen – hier kommt die GPU ins Spiel. GPUs übernehmen diese parallelen Aufgaben, während die CPU sie an die GPU auslagert. Dieser Ansatz, bekannt als heterogene parallele Programmierung, ermöglicht es Host und Device, gemeinsam zu arbeiten.
CUDA, das für NVIDIA-GPUs entwickelt wurde, verwaltet sowohl den Host als auch das Device. Die CPU steuert den Großteil des Programms, leitet jedoch Teile der Berechnung an die GPU weiter, wenn ein Abschnitt parallelisiert werden kann. Die Datenübertragung zwischen CPU und GPU erfolgt über den PCI-Express-Bus, der vergleichsweise langsam ist. Daher werden nur hochgradig parallele Aufgaben an die GPU ausgelagert, um die Effizienz zu maximieren.
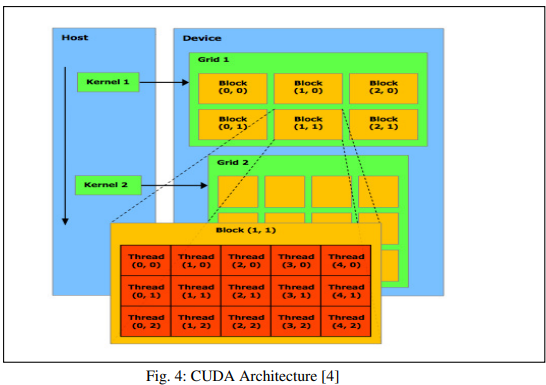
In der Abbildung besteht CUDA aus einer Anordnung von Streaming-Prozessoren, die ein hohes Maß an Threading ermöglichen. Die Anzahl der Streaming-Multiprozessoren (SMs) in jeder GPU kann je nach Generation variieren. Jeder SM enthält mehrere Streaming-Prozessoren (SPs), die sich Steuerlogik und Befehlscache teilen.
Speicherhierarchie
CUDA organisiert den Speicher in verschiedene Ebenen:
- Globaler Speicher: Dies ist der Hauptspeicher der GPU, auch bekannt als Lese- und Schreibspeicher. Er ist für alle Threads zugänglich, jedoch langsamer als andere Speicherarten.
- Gemeinsam genutzter Speicher: Jeder Block von Threads verfügt über seinen eigenen gemeinsam genutzten Speicher, der schneller ist und für Daten genutzt wird, die innerhalb eines Blocks geteilt werden müssen.
- Register: Jeder Thread hat seinen eigenen kleinen Speicher, ein sogenanntes Register, das zur Speicherung thread-spezifischer Daten verwendet wird.
- Konstanter Speicher: In CUDA werden Konstanten und Kernel-Argumente im konstanten Speicher gespeichert, einer speziellen Art von Speicher auf der GPU. Der Zugriff auf diesen Speicher kann langsamer sein als der Zugriff auf Register oder gemeinsam genutzten Speicher, jedoch wird er zwischengespeichert (Caching). Dieses Cache-System beschleunigt die Zugriffszeiten, insbesondere wenn mehrere Threads dieselben Daten lesen, wodurch er trotz seiner geringeren Geschwindigkeit effizient bleibt.
- Texturspeicher: Ein nur lesbarer Speicher, dessen Cache für zweidimensionale räumliche Zugriffsmuster optimiert ist.
Warum nutzen wir GPUs für Deep Learning?
Wir setzen GPUs vor allem wegen ihrer enormen Rechenleistung ein. GPUs bieten zwei wesentliche Vorteile gegenüber CPUs: Sie können eine riesige Anzahl von Berechnungen gleichzeitig ausführen und haben einen sehr schnellen Speicherzugriff, wodurch große Datenmengen effizient verarbeitet werden können. Deep Learning nutzt GPUs, da sie besonders gut für groß angelegte, parallele Berechnungen ausgelegt sind, die für neuronale Netzwerke erforderlich sind. Hier ist der Grund:
Parallele Verarbeitung
Deep-Learning-Modelle, insbesondere tiefe neuronale Netzwerke, erfordern Tausende oder sogar Millionen von Matrixoperationen, wie das Multiplizieren und Addieren großer Zahlenmengen. GPUs sind darauf ausgelegt, diese Aufgaben parallel auf Tausenden von Kernen auszuführen, wodurch sie erheblich schneller arbeiten als CPUs, die diese Aufgaben sequentiell ausführen.
Hoher Durchsatz
Das Training von Deep-Learning-Modellen erfordert die Verarbeitung riesiger Datenmengen, was auf einer CPU sehr zeitaufwendig ist. GPUs können große Datenmengen gleichzeitig verarbeiten und reduzieren dadurch die Trainingszeit von Tagen auf Stunden. Zum Beispiel würde das Training eines Bildverarbeitungsmodells auf einer CPU erheblich länger dauern als auf einer GPU.
Großskalige neuronale Netzwerke
Deep-Learning-Modelle bestehen oft aus zahlreichen Schichten und Parametern (Gewichten), die angepasst werden müssen. Für Modelle wie transformatorbasierte Architekturen (z. B. GPT in Sprachmodellen) ermöglichen GPUs das gleichzeitige Training großer Modelle, indem sie die Last auf viele Kerne verteilen.
Beispiele
- Bildverarbeitung: In Convolutional Neural Networks (CNNs) kann die Verarbeitung eines einzelnen Bildes Millionen von Matrixmultiplikationen erfordern, um Muster zu erkennen. Eine GPU kann diese Berechnungen parallel ausführen, wodurch das Training schneller und effizienter wird.
- Natürliche Sprachverarbeitung (NLP): In Modellen wie GPT oder BERT beschleunigen GPUs das Training von Aufmerksamkeitsmechanismen (Attention Mechanisms), die eine gleichzeitige Berechnung über große Datenfolgen erfordern.
GPU vs. CPU: Wichtige Unterschiede
Der Unterschied in der Rechenleistung zwischen GPUs und CPUs ergibt sich aus ihrem Design für verschiedene Aufgaben:
- GPUs: Entwickelt für die gleichzeitige Bearbeitung vieler Berechnungen. Die meisten GPU-Designs konzentrieren sich auf die Verarbeitung großer Datenmengen, nicht auf die Speicherung oder Verwaltung von Daten.
- CPUs: Entwickelt, um eine geringe Anzahl von Aufgaben gleichzeitig effizient zu verarbeiten und Verzögerungen (Latenz) zu minimieren. Ein großer Teil ihres Designs dient der Verwaltung und Speicherung von Daten, weshalb sie ideal für allgemeine Programme wie Betriebssysteme sind.
Kurz gesagt, während CPUs darauf ausgelegt sind, Verzögerungen zu minimieren und komplexe Aufgaben nacheinander zu bearbeiten, sind GPUs darauf spezialisiert, große Datenmengen parallel zu verarbeiten, indem sie sich auf reine Rechenleistung konzentrieren (mit vielen Kernen für Berechnungen).
CUDA-Installation
Bevor Sie NVIDIA CUDA nutzen können, muss es installiert werden. Dazu sind mehrere Schritte erforderlich. Nachfolgend finden Sie einige allgemeine Schritte zur Installation von CUDA auf persönlichen Geräten.
Schritte zur Installation von CUDA
- Überprüfung der GPU-Kompatibilität: Stellen Sie sicher, dass Ihre Hardware CUDA-kompatibel ist. Prüfen Sie dies auf der NVIDIA-Website.
- Installation der NVIDIA-Treiber: Laden Sie die neuesten NVIDIA-Treiber für Ihre GPU herunter und installieren Sie diese. Diese Treiber sind essenziell, um die CUDA-Funktionalität zu aktivieren.
- Herunterladen des CUDA-Toolkits: Besuchen Sie die NVIDIA CUDA Toolkit-Seite und laden Sie die Version herunter, die mit Ihrem Betriebssystem (Windows, Linux oder macOS) kompatibel ist.
- Installation des Toolkits: Befolgen Sie die Anweisungen in der NVIDIA-Dokumentation, um das CUDA-Toolkit zu installieren. Dies umfasst CUDA-Bibliotheken, Entwicklungstools und die erforderlichen Header-Dateien.
- Einrichten der Umgebungsvariablen: Nach der Installation müssen Sie die CUDA-Pfade (wie
binundlib) zu den Umgebungsvariablen Ihres Systems hinzufügen, damit die CUDA-Programme und Bibliotheken gefunden werden können.
Die H100-GPU: Die nächste Stufe der CUDA-Leistung
NVIDIA-GPUs sind äußerst leistungsstark und führen Tausende von parallelen Berechnungen über zahlreiche Kerne aus. Die Einführung der Hopper-Mikroarchitektur mit der NVIDIA H100 setzt neue Maßstäbe und übertrifft ihre Ampere-Vorgänger wie die A100. Jede neue Architektur bringt erhebliche Verbesserungen in Bezug auf VRAM, CUDA-Kerne und Speicherbandbreite.
Warum die NVIDIA H100 Tensor Core GPU?
Die NVIDIA H100 Tensor Core GPU bietet die zweithöchste PCIe-Speicherbandbreite aller kommerziell verfügbaren GPUs – über 2 TB/s. Mit 80 GB VRAM kann die H100 große Datensätze und Modelle mit unglaublicher Geschwindigkeit verarbeiten, was sie ideal für groß angelegte KI-Anwendungen macht.
Die H100, die auf der Hopper-Architektur basiert, erreicht diese beeindruckende Leistung durch ihre 4. Generation der Tensor-Kerne. Sie verfügt über 640 Tensor-Kerne, 128 Ray-Tracing-Kerne und 14.592 CUDA-Kerne. Diese Kombination ermöglicht eine Rechenleistung von 26 TeraFLOPS bei voller Präzision (FP64).
Zusätzlich unterstützt die H100 verschiedene mathematische Genauigkeiten und kann somit eine breite Palette an Rechenaufgaben effizient bewältigen. Sie ist in der Lage, mit doppelter Präzision (FP64), einfacher Präzision (FP32), halber Präzision (FP16) und Ganzzahlen (INT8) zu arbeiten, was sie zu einer vielseitigen Wahl für unterschiedlichste Berechnungsanforderungen macht.
Fazit
NVIDIAs CUDA ist eine Methode, um komplexe Aufgaben in viele kleine, parallele Aufgaben zu unterteilen, die auf Tausenden von GPU-Kernen gleichzeitig ausgeführt werden. Durch die Nutzung von Threads, Blöcken und Grids wird die Parallelverarbeitung effizient verwaltet, während die Speicherhierarchie sicherstellt, dass die GPU Daten optimal verarbeitet. Diese Architektur macht CUDA ideal für Anwendungen wie Deep Learning, Bildverarbeitung und wissenschaftliche Simulationen, bei denen Geschwindigkeit und parallele Berechnungen entscheidend sind.
Dieser Artikel hat eine Einführung in CUDA gegeben. In naher Zukunft werden wir weitere Artikel veröffentlichen, die einen tieferen Einblick in die Funktionen, Anwendungen und bewährten Methoden zur Optimierung der Leistung in verschiedenen Rechenaufgaben bieten.
