
Eine Einführung in die GPU-Leistungsoptimierung für Deep Learning
Die Rolle von GPUs im Deep Learning
Das GPU-Computing hat Branchen revolutioniert und Fortschritte im angewandten Deep Learning in autonomen Fahrzeugen, Robotik und Molekularbiologie ermöglicht. Die hochleistungsfähigen parallelen Verarbeitungskapazitäten dieser Maschinen beschleunigen die Matrixmultiplikationsberechnungen, die für die Verarbeitung und Umwandlung massiver Datenmengen erforderlich sind, um Modelle zu trainieren und Vorhersagen zu treffen (Inferenzen) mit Deep-Learning-Modellen, die aus Schichten miteinander verbundener Knoten (neuronale Netzwerke) bestehen.
Das Training dieser neuronalen Netzwerke und die Durchführung von Inferenzen schneller und kostengünstiger sind zentrale Prioritäten in der KI-Forschung und -Entwicklung. Im Hinblick auf das GPU-Computing bedeutet dies, die Optimierung der GPU-Leistung besser zu verstehen.
Voraussetzungen
Vertrautheit mit den folgenden Themen wird das Verständnis der in diesem Artikel behandelten Inhalte erleichtern:
- Grundlagen des maschinellen Lernens (ML) und Deep Learning (z. B. Matrixmultiplikation, neuronale Netzwerke, Python, PyTorch)
- Datentypen (INT, FP usw.)
- Neuere NVIDIA-GPU-Architekturen: Blackwell (angekündigt, aber noch nicht verfügbar), Hopper (2022), Ampere (2020)
- CUDA und die GPU-Speicherhierarchie
Einführung in die GPU-Optimierung
Das Ziel dieses Artikels ist es, den Lesern die Einblicke zu geben, die sie benötigen, um ihre Computerleistung zu verbessern. Wer daran interessiert ist, die GPU-Leistung zu optimieren, sollte sich mit den Funktionen der neuesten GPU-Architekturen vertraut machen, die Landschaft der GPU-Programmiersprachen verstehen und sich mit Leistungsüberwachungstools wie NVIDIA Nsight und SMI auseinandersetzen. Das Experimentieren, Benchmarking und wiederholte Optimieren von GPUs sind entscheidend, um eine bessere Nutzung der Hardware zu erreichen.
Nutzung der Hardwarefunktionen von NVIDIA-GPUs
Ein fundiertes Wissen über die Feinheiten der GPU-Architekturen kann das Verständnis für die Programmierung massiv-paralleler Prozessoren verbessern. Mit jeder neuen GPU-Generation hat NVIDIA eine Reihe spezialisierter Hardwarefunktionen eingeführt, um die parallele Verarbeitung weiter zu beschleunigen.
Tensor Cores
Standardmäßig trainieren viele Deep-Learning-Bibliotheken (z. B. PyTorch) mit einfacher Genauigkeit (FP32). Allerdings ist eine einfache Genauigkeit nicht immer erforderlich, um optimale Genauigkeit zu erreichen. Eine geringere Genauigkeit benötigt weniger Speicher, wodurch sich die Geschwindigkeit erhöht, mit der Daten abgerufen werden können (Speicherbandbreite).
Tensor Cores ermöglichen Mixed-Precision-Computing, bei dem FP32 nur dann verwendet wird, wenn es notwendig ist, und der niedrigste Präzisionstyp genutzt wird, der die Genauigkeit nicht beeinträchtigt. Derzeit gibt es fünf Generationen von Tensor Cores, mit der vierten Generation in der Hopper-Architektur und der fünften Generation in der Blackwell-Architektur.
Tensor Core
| Tensor Core | Eingeführter Datentyp |
|---|---|
| Volta (erste Generation) | FP16, FP32 |
| Ampere (dritte Generation) | Sparsity, INT8, INT4, FP64, BF16, TF32 |
| Hopper (vierte Generation) | FP8 |
| Blackwell (fünfte Generation) | FP4 |
Die Transformer Engine
Die Transformer Engine ist eine Bibliothek, die 8-Bit-Floating-Point- (FP8-) Präzision auf Hopper-GPUs ermöglicht. Die Einführung der FP8-Präzision in Hopper-GPUs verbesserte die Leistung gegenüber FP16, ohne die Genauigkeit zu beeinträchtigen. Die zweite Generation der Transformer Engine wird in der Blackwell-Architektur enthalten sein und FP4-Präzision unterstützen.
Tensor Memory Accelerator
Der Tensor Memory Accelerator (TMA) ermöglicht den asynchronen Speichertransfer zwischen dem globalen und dem gemeinsamen Speicher der GPU. Vor der Einführung des TMA arbeiteten mehrere Threads und Warps zusammen, um Daten zu kopieren. Im Gegensatz dazu kann mit dem TMA ein einzelner Thread innerhalb eines Thread-Blocks eine TMA-Anweisung ausgeben, um die Kopieroperation asynchron zu verwalten.
GPUs sind programmierbar
Betrachten Sie Folgendes: Beeinflusst das Hardware-Design die CUDA-Sprache? Oder motiviert die CUDA-Sprache das Hardware-Design? Beides trifft zu. Diese Wechselwirkung zwischen Hardware und Software wird in dem GTC-Vortrag 2022, How CUDA Programming Works, gut beschrieben, in dem Stephen Jones erklärt, dass sich die CUDA-Sprache entwickelt hat, um die physikalischen Gegebenheiten der Hardware programmierbarer zu machen.
CUDA
Die Compute Unified Device Architecture (kurz: CUDA) ist eine Parallel-Computing-Plattform zur Konfiguration von GPUs. CUDA unterstützt neben anderen Programmiersprachen C, C++, Fortran und Python.
CUDA-Bibliotheken
Es gibt eine Vielzahl von Bibliotheken, die auf CUDA aufbauen, um dessen Funktionalität zu erweitern. Einige bemerkenswerte sind:
- cuBLAS: Eine GPU-beschleunigte Bibliothek für grundlegende lineare Algebra (BLAS), die in der Lage ist, Matrixmultiplikationen mit niedriger und gemischter Genauigkeit zu beschleunigen.
- cuDNN (CUDA Deep Neural Network): Eine Bibliothek, die Implementierungen von häufig in DNN-Anwendungen verwendeten Operationen wie Faltung, Aufmerksamkeit, Matrixmultiplikation, Pooling, Tensor-Transformationsfunktionen usw. bereitstellt.
- CUTLASS (CUDA Templates for Linear Algebra Subroutines): Eine Bibliothek, die gemischte Präzision unterstützt und optimierte Operationen für verschiedene Datentypen bietet, darunter Gleitkommazahlen (FP16 bis FP64), Ganzzahlen (4/8-Bit) und binäre Werte (1-Bit). Sie nutzt die Tensor Cores von NVIDIA für hochdurchsatzfähige Matrixmultiplikationen.
- CuTe (CUDA Templates): Eine reine Header-C++-Bibliothek, die Layout- und Tensor-Vorlagen bietet. Diese Abstraktionen kapseln wesentliche Informationen über die Daten wie Typ, Form, Speicherort und Organisation und ermöglichen gleichzeitig komplexe Indizierungsoperationen.
Triton
Triton ist eine Python-basierte Sprache und ein Compiler für parallele Programmierung. Phil Tillet, der Schöpfer von Triton, erklärt in diesem Video, dass die Sprache entwickelt wurde, um die Einschränkungen der GPU-Programmierung im Hinblick auf CUDA und bestehende domänenspezifische Sprachen (DSLs) zu überwinden.
Obwohl CUDA äußerst leistungsfähig ist, ist es oft zu komplex, um direkt damit zu arbeiten – insbesondere für Forscher und Entwickler ohne spezielle GPU-Programmiererfahrung. Diese Komplexität behindert nicht nur die Kommunikation zwischen GPU-Experten und ML-Forschern, sondern erschwert auch die schnelle Iteration, die für die Entwicklung in rechenintensiven Bereichen erforderlich ist.
Darüber hinaus sind bestehende DSLs oft eingeschränkt. Sie bieten keine Unterstützung für benutzerdefinierte Datenstrukturen und erlauben keine Kontrolle über Parallelisierungsstrategien und Ressourcenzuweisungen.
Triton schafft hier einen Ausgleich, indem es seinen Nutzern ermöglicht, Tensoren im SRAM zu definieren und mit Torch-ähnlichen Operatoren zu modifizieren, während es gleichzeitig die Flexibilität bietet, benutzerdefinierte Parallelisierungs- und Ressourcenmanagementstrategien zu implementieren. Triton trägt dazu bei, die GPU-Programmierung zu demokratisieren, indem es ermöglicht, effizienten GPU-Code ohne umfangreiche CUDA-Kenntnisse zu schreiben.
Nutzung der Speicherhierarchie
GPUs verfügen über mehrere Speichertypen mit unterschiedlichen Größen und Geschwindigkeiten. Die umgekehrte Beziehung zwischen Speichergröße und -geschwindigkeit bildet die Grundlage der GPU-Speicherhierarchie. Die strategische Zuordnung von Variablen zu verschiedenen CUDA-Speichertypen gibt Entwicklern mehr Kontrolle über die Leistung ihrer Programme. Der zugewiesene Speichertyp beeinflusst den Gültigkeitsbereich der Variable (auf einen einzelnen Thread beschränkt, innerhalb von Thread-Blöcken geteilt usw.) und die Geschwindigkeit, mit der sie abgerufen wird. Variablen, die im Hochgeschwindigkeitsspeicher wie Registern oder gemeinsam genutztem Speicher abgelegt sind, können schneller abgerufen werden als Variablen in langsameren Speichertypen wie dem globalen Speicher.
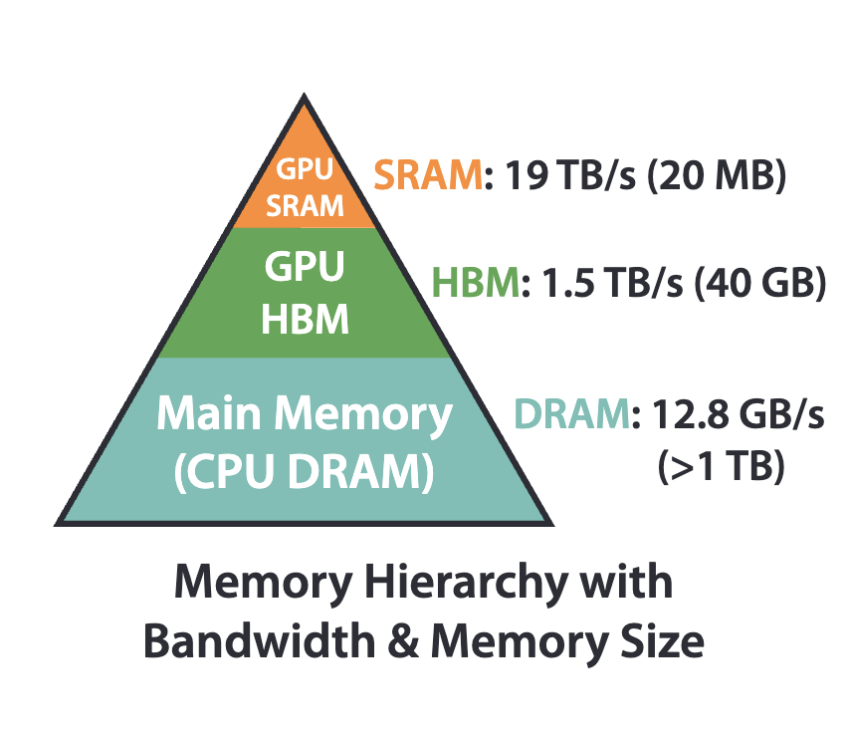
FlashAttention ist ein Beispiel für einen hardwarebewussten Algorithmus, der die Speicherhierarchie ausnutzt.
Was bedeutet GPU-Leistung überhaupt?
Die Leistungsbewertung im GPU-Computing hängt vom jeweiligen Anwendungsfall ab. Dennoch gibt es zentrale Kennzahlen zur Beurteilung der Gesamteffizienz, darunter Latenz und Durchsatz.
Latenz bezeichnet die Zeitverzögerung zwischen Anfrage und Antwort. Im Kontext unseres bevorzugten Parallelprozessors bedeutet dies: Eine Anfrage erfolgt, wenn die GPU einen Befehl zur Verarbeitung erhält, und die Antwort ist das abgeschlossene Rechenergebnis.
Durchsatz gibt an, wie viele Einheiten die GPU pro Sekunde verarbeiten kann. Diese Kennzahl spiegelt die Fähigkeit der GPU wider, mehrere Aufgaben parallel zu bearbeiten. GPU-Architekten und Entwickler arbeiten daran, die Latenz zu minimieren und den Durchsatz zu maximieren.
Diese Kennzahlen werden häufig bei der Benchmarking-Bewertung von GPUs betrachtet. Zum Beispiel analysiert die Studie Benchmarking and Dissecting the Nvidia Hopper GPU Architecture Hopper-GPUs anhand von Latenz- und Durchsatztests für verschiedene Speichereinheiten, Tensor Cores und neue CUDA-Programmierfunktionen, die mit Hopper eingeführt wurden (DPX, asynchrone Datenbewegung und verteiltes Shared Memory).

A100 GPU-Speicherbandbreite vs. FLOPs
Aus Stephen Jones’ GTC-Vortrag 2022 How CUDA Programming Works: Floating Point Operations Per Second (FLOPs) werden oft als Leistungsmaß herangezogen, sind jedoch selten der begrenzende Faktor. GPUs verfügen in der Regel über eine enorme Gleitkomma-Rechenleistung, sodass andere Aspekte wie die Speicherbandbreite oft die bedeutenderen Engpässe darstellen.
Leistungsüberwachungstools
Die Überwachung der GPU-Leistung ermöglicht es Entwicklern und Systemadministratoren, Engpässe zu identifizieren (ist die Aufgabe speichergebunden, latenzgebunden oder rechengebunden?), GPU-Ressourcen effizient zuzuweisen, Überhitzung zu verhindern, den Energieverbrauch zu verwalten und fundierte Entscheidungen über Hardware-Upgrades zu treffen. NVIDIA stellt zwei leistungsstarke Tools zur GPU-Überwachung bereit: Nsight und SMI.
NVIDIA Nsight
Das NVIDIA Nsight Systems ist ein systemweites Leistungsanalysetool, das die Visualisierung der Algorithmen einer Anwendung sowie die Identifizierung von Optimierungspotenzialen ermöglicht. Weitere Informationen zu NVIDIA Nsight Compute finden Sie im Kernel-Profiling-Guide.
NVIDIA System Management Interface
Das NVIDIA System Management Interface (nvidia-smi) ist ein Kommandozeilentool, das auf der NVIDIA Management Library basiert und zur Verwaltung sowie Überwachung von GPU-Geräten dient. Weitere Informationen finden Sie in der nvidia-smi-Dokumentation.

Fazit
Dieser Artikel ist keineswegs eine vollständige Abhandlung über die GPU-Optimierung, sondern vielmehr eine Einführung in das Thema. Es wird empfohlen, die im Artikel und im Referenzabschnitt verlinkten Ressourcen zu erkunden, um das Verständnis weiter zu vertiefen. Weitere Artikel folgen!
Referenzen
NVIDIA Blogs/Dokumentation
- Unterschied zwischen Deep Learning Training und Inferenz
- Deep Learning Performance: Matrixmultiplikation
- Übersicht über Tensor Cores
- Mixed Precision Training
- Transformer Engine Benutzerhandbuch
- GPU-beschleunigte Bibliotheken
- cuBLAS
- cuDNN
- CUTLASS
- Verbesserung der GPU-Leistung durch Reduzierung von Anweisungen
- NVIDIA System Management Interface
Fachartikel
- Benchmarking und Analyse der Nvidia Hopper GPU-Architektur
- Eine Fallstudie zur CUDA-Kernel-Fusion: Implementierung von FlashAttention-2 auf der NVIDIA Hopper-Architektur mit der CUTLASS-Bibliothek
- FlashAttention: Schnelle und speichereffiziente exakte Aufmerksamkeit mit IO-Awareness
Weitere hilfreiche Ressourcen
- Programming Massively Parallel Processors (4. Auflage)
- GPU Mode YouTube-Kanal und Discord-Server (ehemals CUDA Mode)
- Blogpost von Tim Dettmers: Welche GPU(s) für Deep Learning? Meine Erfahrungen und Empfehlungen
- THE TRITON LANGUAGE | PHILIPPE TILLET
- Notizen zur GPU-Optimierung
- CUTLASS-Tutorial: NVIDIA® Tensor Memory Accelerator (TMA) meistern
- Wie CUDA-Programmierung funktioniert
- FreeCodeCamp-Kurs von Elliot Arledge: CUDA-Programmierkurs – Hochleistungsrechnen mit GPUs
