
GPUs und Parallele Verarbeitung: Verständnis von Warps
GPUs werden als parallele Prozessoren beschrieben, da sie Aufgaben gleichzeitig ausführen können. Mehrere Verarbeitungseinheiten unterteilen Aufgaben in kleinere Teilaufgaben, führen sie gleichzeitig aus und kombinieren die Ergebnisse zu einem endgültigen Resultat. Threads, Warps, Thread-Blöcke, Kerne und Multiprozessoren teilen sich dabei Ressourcen wie Speicher, was ihre Zusammenarbeit erleichtert und die gesamte Effizienz der GPU steigert.
Die Rolle von Warps in der parallelen Verarbeitung
Eine besonders wichtige Einheit sind Warps, die ein Grundpfeiler der parallelen Verarbeitung sind. Durch die Gruppierung von Threads in eine einzige Ausführungseinheit ermöglichen Warps eine Vereinfachung des Thread-Managements, die gemeinsame Nutzung von Daten und Ressourcen sowie die Maskierung von Speicherlatenzen durch effektive Planung.

„Der Begriff Warp stammt aus der Weberei, der ersten parallelen Fadentechnologie.“
Optimierung der GPU-Leistung mit Warps
In diesem Artikel erläutern wir, wie Warps zur Optimierung der Leistung GPU-beschleunigter Anwendungen beitragen. Durch ein besseres Verständnis von Warps können Entwickler erhebliche Verbesserungen bei Rechengeschwindigkeit und Effizienz erzielen.
Warps entschlüsselt
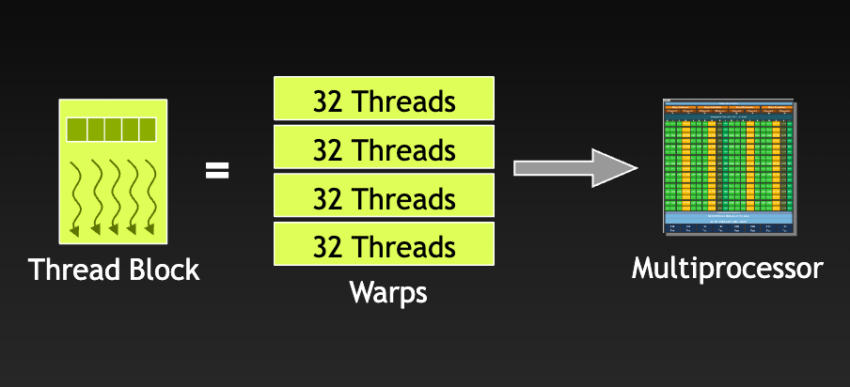
Thread-Blöcke werden in Warps unterteilt, die jeweils aus 32 Threads bestehen. Alle Threads in einem Warp laufen auf demselben Streaming-Multiprozessor. Abbildung aus einer NVIDIA-Präsentation über GPGPU UND BESCHLEUNIGER-TRENDS.
Wenn ein Streaming-Multiprozessor (SM) mit der Ausführung von Thread-Blöcken beauftragt wird, unterteilt er die Threads in Warps. Moderne GPU-Architekturen haben typischerweise eine Warp-Größe von 32 Threads.
Die Anzahl der Warps in einem Thread-Block hängt von der vom CUDA-Programmierer konfigurierten Blockgröße ab. Wenn beispielsweise die Größe des Thread-Blocks 96 Threads beträgt und die Warp-Größe 32 Threads ist, ergibt sich: 96 Threads / 32 Threads pro Warp = 3 Warps pro Thread-Block.
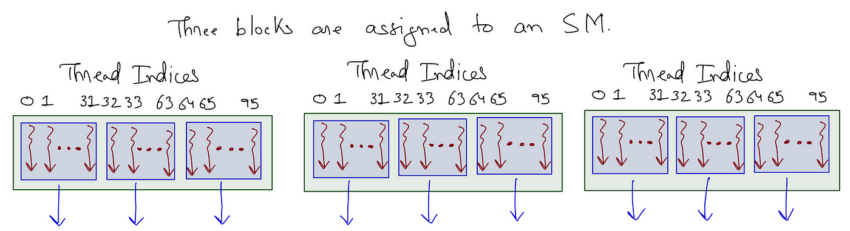
In dieser Abbildung werden drei Thread-Blöcke dem SM zugewiesen. Die Thread-Blöcke bestehen jeweils aus drei Warps. Ein Warp enthält 32 aufeinanderfolgende Threads. Abbildung aus einem Medium-Artikel.
Beachten Sie, wie die Threads in der Abbildung durchnummeriert sind, beginnend bei 0 und fortlaufend zwischen den Warps innerhalb des Thread-Blocks. Der erste Warp besteht aus den ersten 32 Threads (0–31), der nächste Warp aus den folgenden 32 Threads (32–63) und so weiter.
GPUs: SIMD oder SIMT?
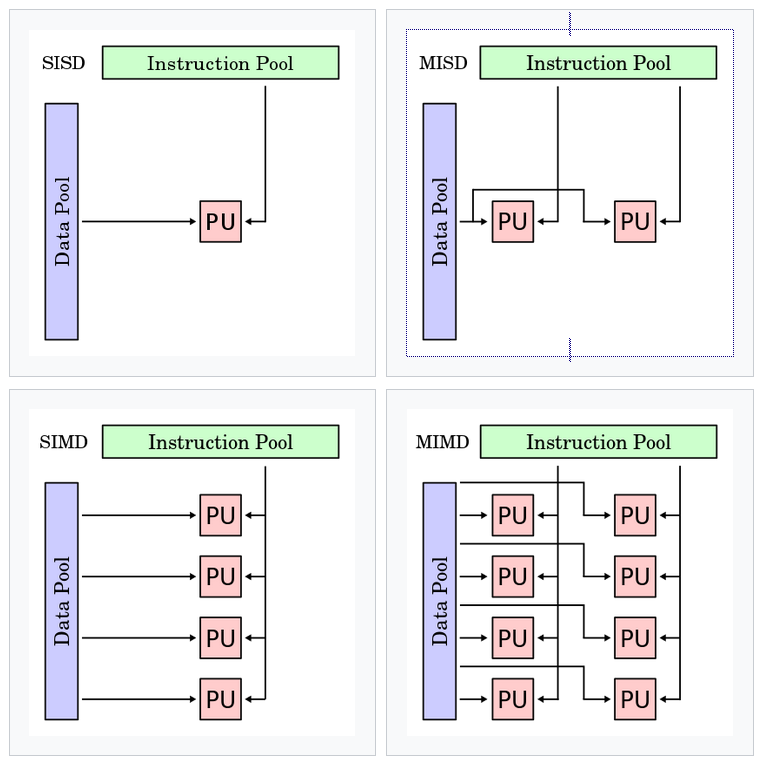
Flynn’s Taxonomy ist ein Klassifikationssystem, das auf der Anzahl der Instruktions- und Datenströme einer Computerarchitektur basiert. Es gibt vier Klassen: SISD (Single Instruction Single Data), SIMD (Single Instruction Multiple Data), MISD (Multiple Instruction Single Data) und MIMD (Multiple Instruction Multiple Data). Abbildung aus dem PEP root6 Workshop des CERN.
GPUs werden oft als Single Instruction Multiple Data (SIMD) beschrieben, was bedeutet, dass sie dieselbe Operation gleichzeitig auf mehreren Datenoperanden ausführen. Single Instruction Multiple Thread (SIMT), ein von NVIDIA geprägter Begriff, erweitert Flynn’s Taxonomy, um die Thread-Ebene-Parallelität von NVIDIA-GPUs besser zu beschreiben.
Während sowohl SIMD als auch SIMT Datenparallelität nutzen, unterscheiden sie sich in ihrem Ansatz. SIMD eignet sich besonders für einheitliche Datenverarbeitung, während SIMT durch dynamisches Thread-Management und bedingte Ausführung eine höhere Flexibilität bietet.
Warp-Scheduling versteckt Latenz
Im Kontext von Warps bezeichnet Latenz die Anzahl der Taktzyklen, die ein Warp benötigt, um eine Instruktion auszuführen und für die nächste verfügbar zu sein.
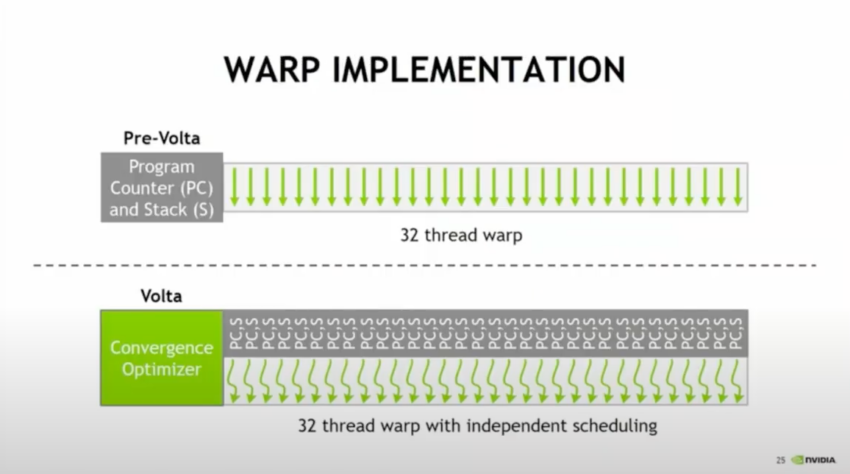
Pre-Volta-GPUs hatten einen einzigen Program Counter für einen 32-Thread-Warp. Mit der Einführung der Volta-Mikroarchitektur erhielt jeder Thread seinen eigenen Program Counter. Wie Stephen Jones in seinem GTC ’17 Vortrag beschreibt: „Jetzt sind all diese Threads völlig unabhängig – sie funktionieren zwar besser, wenn Sie sie gruppieren … aber Sie sind nicht mehr verloren, wenn Sie sie aufteilen.“ Abbildung aus Inside Volta GPUs (GTC ’17).
Program Counter
Program Counter erhöhen sich in jedem Instruktionszyklus, um die Programmsequenz aus dem Speicher abzurufen und den Ablauf der Programmausführung zu steuern. Während Threads in einem Warp eine gemeinsame Startadresse haben, besitzen sie jeweils eigene Program Counter, die eine unabhängige Ausführung und Verzweigung ermöglichen.
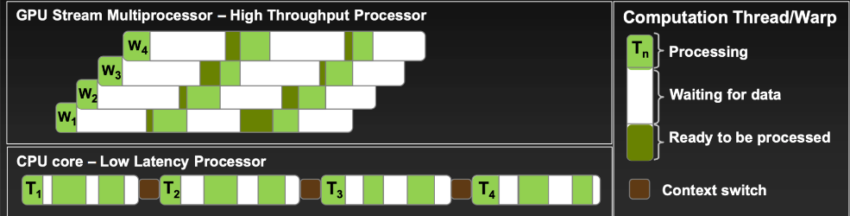
W steht für Warp und T für Thread. GPUs nutzen Warp-Scheduling, um Latenzen zu verbergen, während CPUs sequenziell mit Kontextwechsel arbeiten. Abbildung aus Vorlesung 6 von CalTechs CS179.
Alle Warp-Scheduler erreichen die maximale Auslastung, wenn sie in jedem Taktzyklus kontinuierlich Instruktionen ausgeben. Die Anzahl der aktiven Warps – also der Warps, die der SM zu einem bestimmten Zeitpunkt ausführt – beeinflusst die Auslastung direkt. Mit anderen Worten: Es müssen ausreichend Warps vorhanden sein, damit die Warp-Scheduler Instruktionen zuweisen können. Mehrere aktive Warps ermöglichen es dem SM, zwischen ihnen zu wechseln, wodurch Latenzen verborgen und der Durchsatz maximiert werden.
Branching
Separate Program Counter ermöglichen das sogenannte Branching – eine if-then-else-Programmstruktur, bei der nur aktive Threads bestimmte Anweisungen ausführen. Entwickler erzielen die beste Leistung, wenn alle 32 Threads eines Warps dieselbe Instruktion ausführen. Daher sollten sie den Code so schreiben, dass Abweichungen innerhalb eines Warps minimiert werden.
Fazit: Die Fäden zusammenführen
Warps spielen eine entscheidende Rolle in der GPU-Programmierung. Diese 32-Thread-Einheit nutzt SIMT, um die Effizienz der parallelen Verarbeitung zu steigern. Ein effektives Warp-Scheduling versteckt Latenzen und maximiert den Durchsatz, wodurch komplexe Arbeitslasten effizienter ausgeführt werden können. Zudem ermöglichen Program Counter und Branching eine flexible Thread-Verwaltung. Trotz dieser Flexibilität sollten Entwickler vermeiden, dass Threads innerhalb eines Warps über lange Sequenzen hinweg unterschiedliche Pfade nehmen.
