
Die Geschichte der Innovation im Computing: FlashAttention und FlashAttention-2
Einleitung
Die Geschichte der Innovation im Computing ist geprägt von Beispielen für Optimierungen, die offensichtlich erscheinen, aber jahrelang im Verborgenen lagen.
FlashAttention (2022) ist ein Beispiel für einen solchen Durchbruch. Viele Forscher konzentrierten sich auf die Reduzierung von FLOPs durch Näherungstechniken. Doch Tri Dao und das FlashAttention-Team erkannten, dass der Engpass in redundanten Speicherzugriffen zwischen GPU-HBM und SRAM lag. FlashAttention kombinierte klassische Techniken (Kernel-Fusion und Tiling), um eine Beschleunigung der Echtzeitberechnung von Attention zu erreichen, ohne die Genauigkeit (wie bei Näherungsmethoden) zu beeinträchtigen.
FlashAttention-2 (2023) ging mit seinem hardware- und IO-bewussten Ansatz noch einen Schritt weiter und erzielte eine 2-fache Beschleunigung gegenüber seinem Vorgänger.
Dieser Artikel erläutert, wie FlashAttention-2 Verbesserungen gegenüber FlashAttention erreicht hat. Die folgenden Änderungen am Algorithmus werden detailliert besprochen:
- Reduzierung von Nicht-Matmul-FLOPs, um eine hohe Durchsatzrate zu gewährleisten
- Anpassung der Arbeitsaufteilung zwischen Warps zur Reduzierung von Speicherzugriffen
- Erhöhung der Belegung durch bessere Parallelisierung
Voraussetzungen
Wir empfehlen den vorherigen Artikel zu FlashAttention zu lesen und zu verstehen, bevor Sie fortfahren. Ein Verständnis der GPU-Leistungsoptimierung, der GPU-Speicherhierarchie und von Warps könnte ebenfalls hilfreich sein.
Reduzierung von Nicht-Matmul-FLOPs, um eine hohe Durchsatzrate zu gewährleisten
Die Aufrechterhaltung einer hohen Durchsatzrate, also der Geschwindigkeit, mit der ein System (GPU) Daten verarbeiten oder Operationen ausführen kann, ist entscheidend für die Bewältigung steigender Arbeitslasten. Um eine hohe Durchsatzrate zu erreichen, müssen Programme so gestaltet sein, dass sie die Rechenressourcen effizient nutzen.
Zum Beispiel verfügen NVIDIA-GPUs über hochspezialisierte Verarbeitungseinheiten namens Tensor Cores, die Matrixmultiplikationen beschleunigen. Gleitkommaoperationen, die keine Matrixmultiplikation sind (Nicht-Matmul-FLOPs), werden jedoch von diesen spezialisierten Einheiten nicht beschleunigt und benötigen daher mehr Zeit. Durch die Eliminierung von Nicht-Matmul-Operationen, die nicht die Rechenleistung der Tensor Cores nutzen können, bleibt die Durchsatzrate hoch.
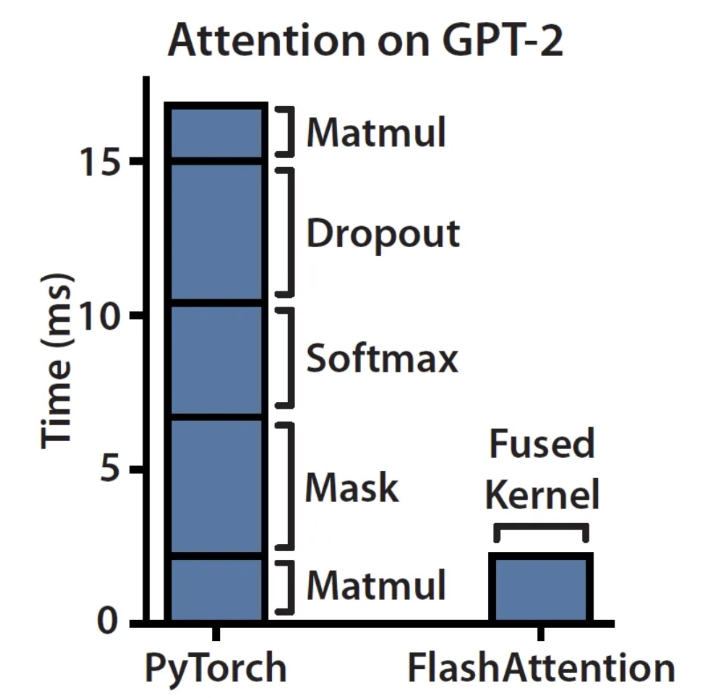
Diese Abbildung veranschaulicht, dass die Attention-Berechnung die meiste Zeit für Nicht-Matmul-Operationen benötigt.
FlashAttention-2 minimiert gezielt Nicht-Matmul-FLOPs, indem es strategisch Bereiche identifiziert, die sich ändern lassen, ohne das Endergebnis zu beeinflussen. Zu diesem Zweck passt FlashAttention-2 die Berechnung von Online-Softmax an.
In FlashAttention berechnet das System Softmax blockweise und verfolgt zusätzliche Statistiken (m, l), um die Ausgabe entsprechend zu reskalieren. Anschließend summiert es die Ausgaben aller Einzelblöcke, um das korrekte Ergebnis zu erhalten. Im Gegensatz dazu bewahrt FlashAttention-2 eine unskalierte Version der Ausgabe bis zum Ende der Schleife und skaliert sie erst dann, um das korrekte Ergebnis zu liefern.

Zusätzlich speichert FlashAttention-2 anstelle der Maxima 𝑚^(𝑗) und der Summe der Exponentialfunktionen ℓ^(𝑗) für den Rückwärtsdurchlauf nur logsumexp, das aus den weggelassenen Variablen besteht.
Arbeitsaufteilung zwischen Warps zur Reduzierung von Speicherzugriffen anpassen
Ein Thread besteht aus dem Code des Programms, dem aktuellen Ausführungspunkt im Code sowie den Werten seiner Variablen und Datenstrukturen. Diese Threads werden in Thread-Blöcken organisiert und von einem Streaming-Multiprozessor ausgeführt, der Hunderte dieser Threads gleichzeitig ausführt.
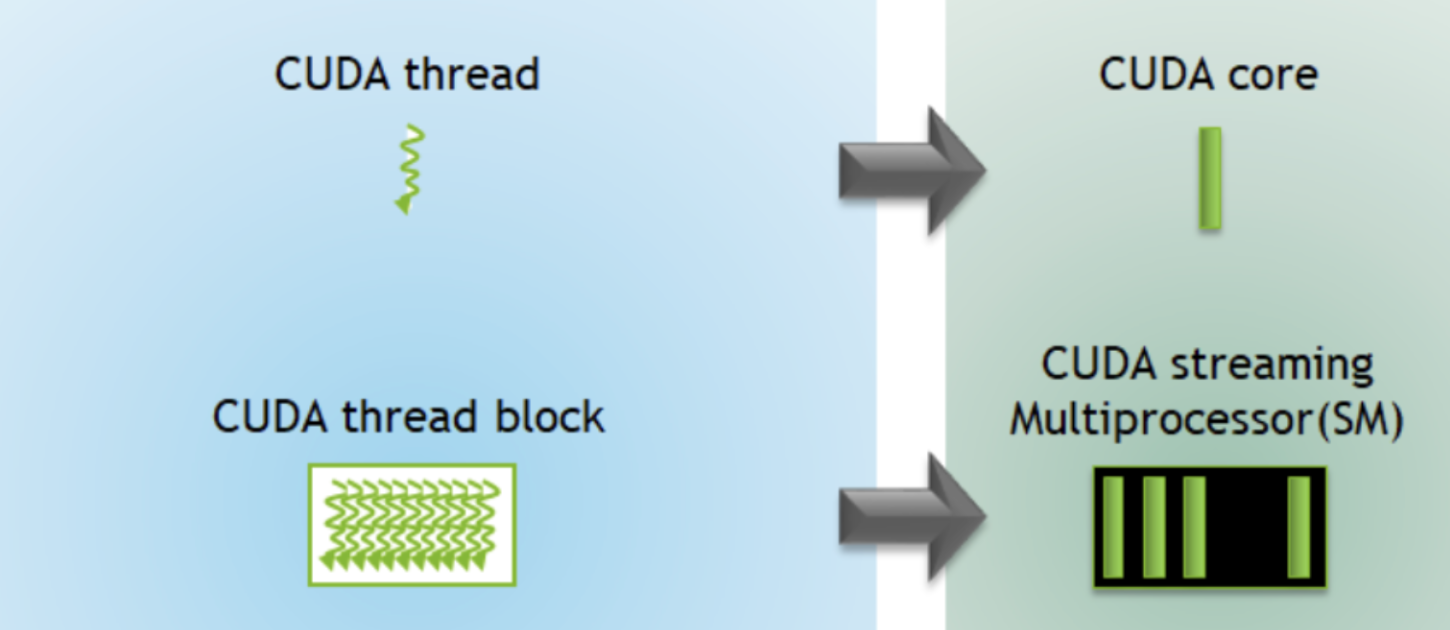
Das Thread-Management auf Warp-Ebene ist dank des Single-Instruction-Multiple-Thread-(SIMT)-Ausführungsmodells von NVIDIA-GPUs möglich. Dabei wird eine Anweisung von mehreren Threads in Form eines 32-Thread-Warps ausgeführt. Threads innerhalb eines Warps können zusammenarbeiten, um Aufgaben wie Matrixmultiplikationen auszuführen. Warps können auch miteinander kommunizieren, indem sie aus dem gemeinsamen Speicher lesen oder in ihn schreiben.

Das Zuweisen von Arbeit an Warps beinhaltet das Aufteilen großer Berechnungen in kleinere Aufgaben, die über diese Thread-Gruppen gleichzeitig ausgeführt werden. Eine schlechte Aufgabenverteilung kann zu redundanten Speicherzugriffen führen. FlashAttention-2 zielt darauf ab, Speicherzugriffe durch strategische Partitionierung der Attention-Berechnung zwischen Warps zu reduzieren.
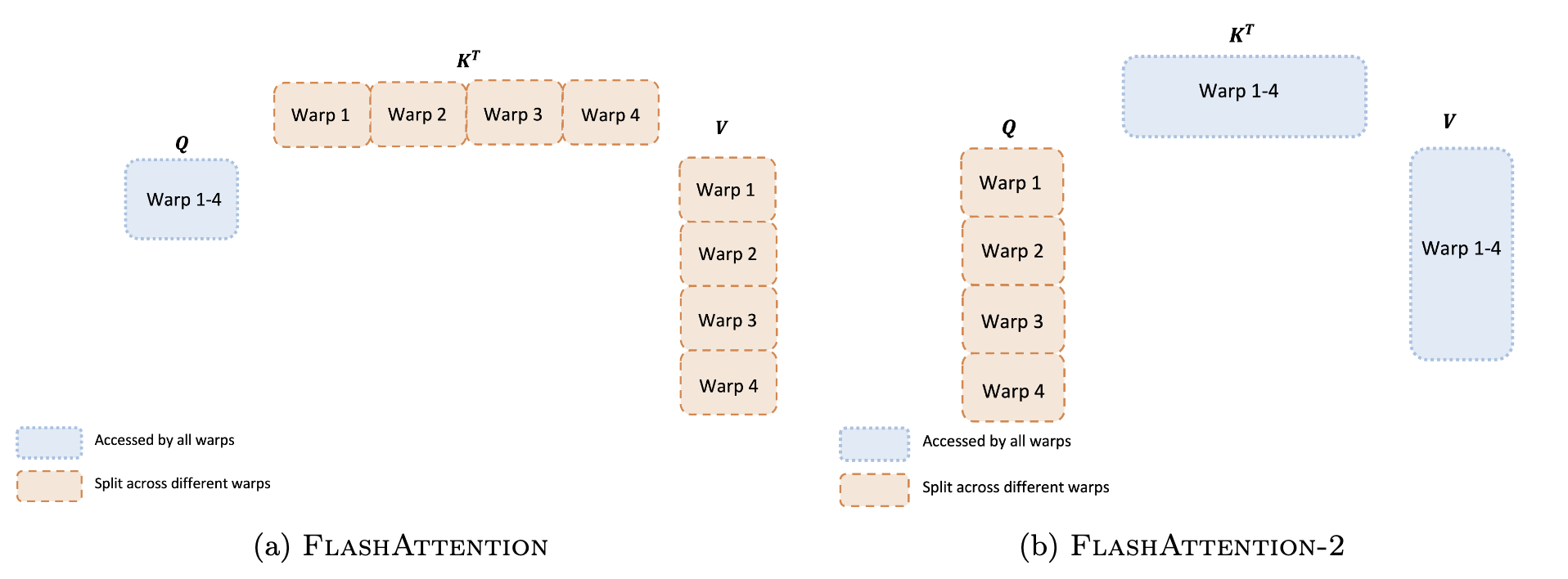
| Frage | FlashAttention (Split-K) | FlashAttention-2 (Split-Q) |
|---|---|---|
| Welche Matrix/ welche Matrizen werden auf 4 Warps aufgeteilt? | K und V | Q |
| Welche Matrix/ welche Matrizen sind für alle 4 Warps zugänglich? | Q | K und V |
| Wie wird \(QK^T\) berechnet? | Jede der 4 Warps multipliziert mit den anderen, um eine Teilsumme von \(QK^T\) zu erhalten. | Jede Warp berechnet ihren eigenen Abschnitt von \(QK^T\). |
| Ist Synchronisation und Kommunikation zwischen den Warps notwendig? | Ja, alle 4 Warps müssen ihre Zwischenergebnisse im Shared Memory speichern, synchronisieren und zusammenrechnen. | Im Vorwärtsdurchlauf ist keine Kommunikation oder Synchronisation zwischen Warps erforderlich. Jede Warp kann ihr Ergebnis direkt mit V multiplizieren, um die Ausgabe zu erhalten. Im Rückwärtsdurchlauf ist jedoch eine gewisse Synchronisation erforderlich, um die komplexe Abhängigkeit zwischen allen Eingaben und Gradienten zu berücksichtigen. |
| Was bedeutet das für die Geschwindigkeit? | Der Vorwärtsdurchlauf wird durch mehrere Lese- und Schreibvorgänge im Shared Memory verlangsamt. | Das gemeinsame Nutzen von \(K^T\) und \(V\) unter den Warps sowie das Aufteilen von \(Q\) eliminieren Shared Memory-Lese-/Schreibvorgänge zwischen Warps, was zu einer Geschwindigkeitssteigerung gegenüber FlashAttention sowohl im Vorwärts- als auch im Rückwärtsdurchlauf führt. |
Erhöhung der Belegung durch bessere Parallelisierung
Die Belegung ist das Verhältnis der Anzahl der Warps, die einem Streaming-Multiprozessor zugewiesen werden, zur maximalen Anzahl der unterstützten Warps. Speichergebundene Operationen, wie der Softmax-Schritt der Attention-Berechnung, erfordern typischerweise eine höhere Belegung.
Die 108 Streaming-Multiprozessoren der A100-GPU arbeiten effizient mit mindestens 80 Thread-Blöcken. Weniger Thread-Blöcke können dazu führen, dass Streaming-Multiprozessoren untätig bleiben und die Rechenkapazität der GPU nicht vollständig ausgenutzt wird.
Um die Belegung zu erhöhen, hat FlashAttention-2 eine Parallelisierung über die Sequenzlänge integriert. Hierbei handelt es sich um die gleichzeitige Ausführung unabhängiger Aufgaben über Thread-Blöcke, die keine Synchronisation zwischen ihnen erfordern.
Vergleich der Parallelisierungsstrategien
| Parallelisierung über | FlashAttention | FlashAttention-2 |
|---|---|---|
| Batch-Größe (Anzahl der Eingabesequenzen pro Batch) | ✔️ | ✔️ |
| Head-Dimension (Anzahl der Attention-Heads) | ✔️ | ✔️ |
| Sequenzlänge (Anzahl der Elemente in einer Eingabesequenz) | ❌ | ✔️ |
Während FlashAttention nur über die Batch-Größe und die Head-Dimension parallelisiert, erweitert FlashAttention-2 dies um die Sequenzlänge. Dadurch erhöht sich die Anzahl der aktiven Thread-Blöcke von batch_size * head_dimension auf batch_size * head_dimension * sequence_length.
Warum ist Parallelisierung über die Sequenzlänge wichtig?
Eine lange Sequenzlänge bedeutet eine kleinere Batch-Größe, da weniger Eingabesequenzen in einen Batch passen. Bei FlashAttention reduziert dies die Anzahl der aktiven Thread-Blöcke, da sie durch batch_size * head_dimension begrenzt sind. Durch die zusätzliche Parallelisierung über die Sequenzlänge in FlashAttention-2 wird die Nutzung der Streaming-Multiprozessoren verbessert.
Loop-Reversal: Umkehrung der Schleifenreihenfolge
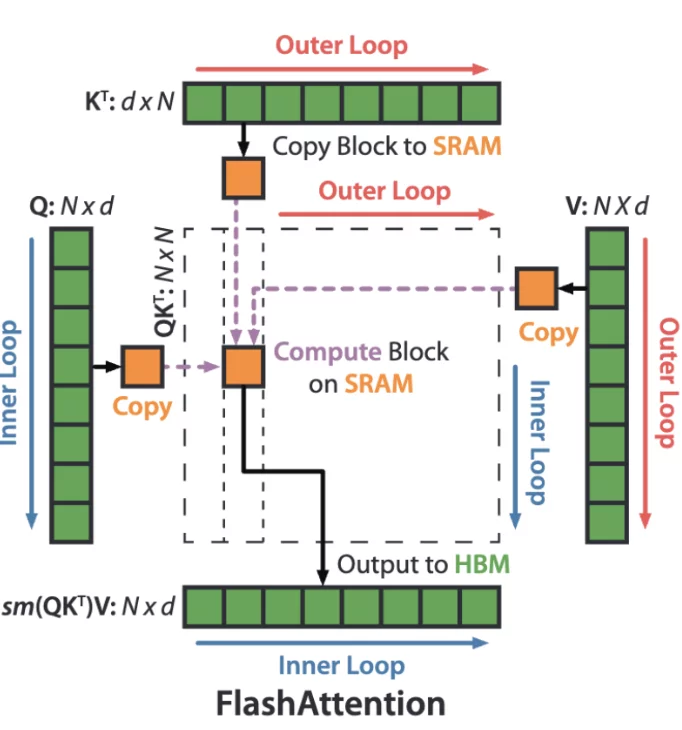
FlashAttention durchläuft die Blöcke der Matrizen K und V in einer äußeren Schleife (rote Pfeile) und lädt sie in den schnellen SRAM-Speicher. Innerhalb jedes Blocks iteriert FlashAttention über die Blöcke der Q-Matrix (blaue Pfeile), lädt sie in den SRAM und schreibt die berechnete Attention zurück in den HBM-Speicher. FlashAttention-2 kehrt diese Reihenfolge um.
| Schleifenebene | FlashAttention | FlashAttention-2 |
|---|---|---|
| Äußere Schleife | Über K, V Blöcke | Über Q Blöcke |
| Innere Schleife | Über Q Blöcke | Über K, V Blöcke |
Diese Optimierung wurde ursprünglich von Phil Tillet in Triton implementiert. Sie ermöglicht eine effizientere Berechnung der Attention-Matrix.
Parallelisierung im Vorwärts- und Rückwärtsdurchlauf
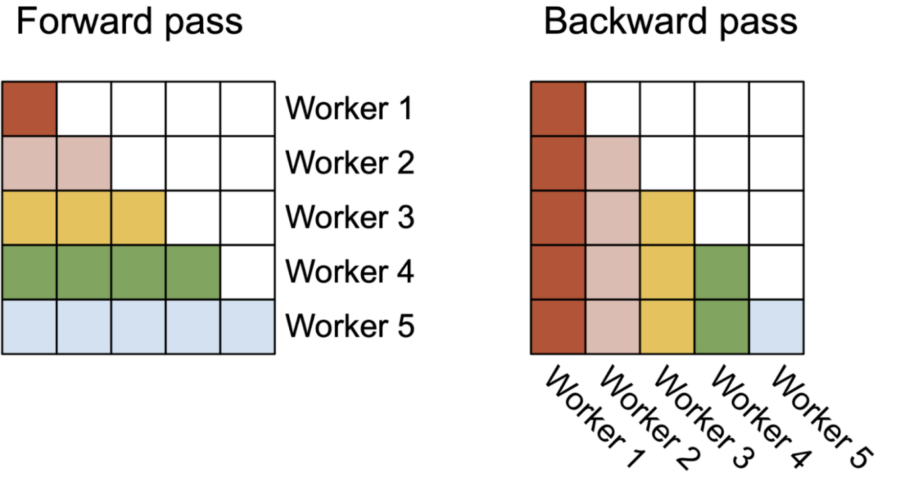
Die folgende Abbildung zeigt, wie die Parallelisierung im Vorwärts- und Rückwärtsdurchlauf umgesetzt wird:
- Vorwärtsdurchlauf: Jeder Thread-Block verarbeitet eine Reihe von Zeilen der Attention-Matrix (äußere Schleife).
- Rückwärtsdurchlauf: Jeder Thread-Block verarbeitet eine Reihe von Spalten der Attention-Matrix (innere Schleife).
Fazit
Zusammenfassend beschleunigt FlashAttention-2 die Berechnung gegenüber FlashAttention, indem es die Anzahl der Nicht-Matmul-FLOPs reduziert, um eine hohe Durchsatzrate zu gewährleisten, die Sequenzlängen-Parallelisierung hinzufügt, um die Belegung zu erhöhen, und die Arbeit zwischen verschiedenen Warps eines Thread-Blocks aufteilt, um Kommunikation und Speicherzugriffe zu minimieren.
Der Erfolg von FlashAttention und seinem Nachfolger FlashAttention-2 zeigt, dass die Arbeit mit der Hardware und nicht gegen sie zu besseren Ergebnissen führt. Wenn wir die Systeme, auf denen wir aufbauen, wirklich verstehen, anstatt sie als abstrakte Blackboxes zu behandeln, können wir erstaunliche technologische Fortschritte erzielen.
