
CODEGEN: Ein Transformatives Open-Source-Sprachmodell für Vielseitige Programmsynthese
Mit dem Aufstieg großer Sprachmodelle (LLMs) denken wir anders und gehen viele Aufgaben neu an – von der Verarbeitung natürlicher Sprache und der Texterstellung bis hin zur Programmierung. Von OpenAIs GPT-3 und GPT-4 über Anthropic Claude, Googles PaLM bis hin zu Apples Certainly befinden wir uns in einer Post-LLM-Ära.
Einführung in CODEGEN: Open-Source-LLM für Programmsynthese
Eines der spannendsten Werkzeuge ist ein Open-Source-LLM für die Programmsynthese, das den Zugang zum Programmieren demokratisiert hat. Es heißt CODEGEN. CODEGEN wurde vom Salesforce Research Team entwickelt. In diesem Artikel werden wir seine Fähigkeiten und die Auswirkungen auf die Zukunft der Programmierung untersuchen.
Voraussetzungen
Um die Konzepte in diesem Artikel zu verstehen, ist Vertrautheit mit folgenden Themen erforderlich:
- Programmiersprachen: Grundkenntnisse in Python oder einer anderen gängigen Sprache.
- Sprachmodelle: Allgemeines Wissen über GPT oder Transformer-basierte Architekturen.
- Open-Source-Tools: Erfahrung mit GitHub-Repositories und grundlegender Code-Deployment.
CODEGEN: Demokratisierung der Programmsynthese
Leistungsstarke Sprachmodelle für die Programmsynthese wurden durch mangelnde Trainingsressourcen und Daten eingeschränkt – nun hat das Salesforce Research Team mit einer Familie von LLMs namens CODEGEN begonnen, dieses Problem zu lösen. Diese Modelle haben eine Größe von 1,5 Milliarden bis 16,1 Milliarden Parametern.
Die Innovation hinter CODEGEN liegt im umfassenden Training. Es nutzt umfangreiche Textsammlungen in natürlicher Sprache und Programmiersprachen, wodurch CODEGEN ein tiefes Verständnis für menschliche Sprache und Code erlangt. Dadurch ist es in der Lage, viele Aufgaben der Programmsynthese mit hoher Präzision zu bewältigen.
CODEGENs Leistung im HumanEval Benchmark
Der beeindruckendste Aspekt von CODEGEN ist seine herausragende Leistung im HumanEval Benchmark, dem De-facto-Standard für die Bewertung von Zero-Shot-Codegenerierung. Durch das Übertreffen modernster Modelle zeigt CODEGEN das Potenzial, hochwertigen und funktionalen Code ohne spezielle Feinabstimmung zu generieren.
Mehrstufiger Trainingsansatz von CODEGEN für Verbesserte Programmsynthese
Die Transformer-basierte Architektur von CODEGEN nutzt Selbstaufmerksamkeitsmechanismen, um komplexe Beziehungen in natürlicher Sprache und Code zu erfassen. Was CODEGEN einzigartig macht, ist sein mehrstufiger Trainingsansatz, der es ermöglicht, Codes in verschiedenen Programmiersprachen mit hoher Kompetenz zu verstehen und zu erzeugen. Die drei zentralen Phasen des Trainingsprozesses von CODEGEN sind:
Drei Phasen des CODEGEN-Trainings
- CODEGEN-NL: Zunächst vortrainiert auf The Pile, einem umfangreichen, kuratierten Datensatz, der auch Code-Daten enthält. Diese Phase bildet die Grundlage für das Verständnis natürlicher Sprache.
- CODEGEN-MULTI: Aufbauend auf CODEGEN-NL umfasst diese Phase das Training mit BigQuery, einem Datensatz mit Code aus verschiedenen Programmiersprachen, darunter C, C++, Go, Java, JavaScript und Python.
- CODEGEN-MONO: Die letzte Phase konzentriert sich auf Python-spezifische Fähigkeiten durch das Training mit BigPython, einem Datensatz aus Python-Code von GitHub-Repositories.
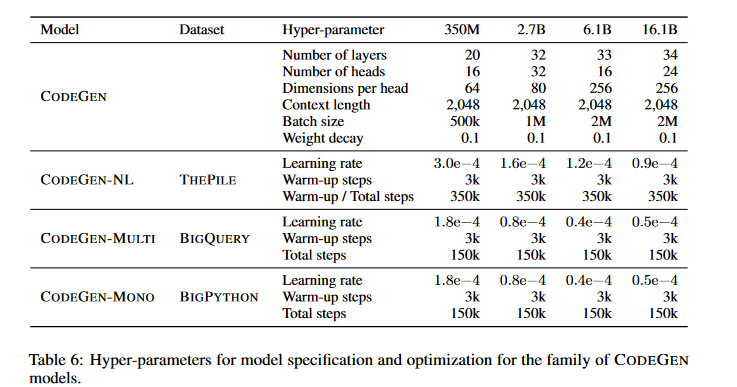
Durch den sequenziellen Trainingsansatz kann CODEGEN sowohl natürliche Sprache als auch verschiedene Programmiersprachen verstehen. Dadurch eignet es sich hervorragend für Aufgaben der Programmsynthese.
Das Potenzial der Multi-Turn-Programmsynthese
Die Multi-Turn-Programmsynthese stellt eine innovative Methode zur Code-Erstellung dar. Bei diesem Ansatz interagieren Nutzer und Systeme iterativ, um Programme schrittweise zu entwickeln, zu verfeinern und zu korrigieren.
Im Gegensatz zu herkömmlichen Single-Turn-Techniken, bei denen vollständige Code-Snippets aus einzelnen Eingaben generiert werden, ermöglicht Multi-Turn-Synthese eine interaktive Entwicklung. Dadurch können komplexere und genauere Programme erstellt werden.
Schlüsselaspekte der Multi-Turn-Programmsynthese
Hier sind einige zentrale Konzepte der Multi-Turn-Programmsynthese:
- Iterative Verfeinerung: Multi-Turn-Synthese nutzt die zyklische Interaktion zwischen Mensch und Maschine. Das Modell generiert auf Grundlage einer ersten Eingabe oder einer allgemeinen Beschreibung einen ersten Code-Entwurf. Anschließend kann der Nutzer die Eingabe verfeinern, Änderungen vornehmen oder Korrekturen anfordern – so entsteht schrittweise ein optimierter Code.
- Dialogbasierte Interaktion: Dieser Ansatz basiert auf einem interaktiven Austausch, bei dem das Modell gezielte Rückfragen stellt, um die Anforderungen des Nutzers besser zu verstehen. Der Nutzer gibt zusätzliche Informationen, und das Modell aktualisiert den Code entsprechend.
- Kontextbewahrung: Die Fähigkeit des Systems, den Kontext eines Gesprächs zu bewahren, ist entscheidend, um die Absichten des Nutzers zu erfassen und Änderungen effizient zu integrieren. Dies ist besonders wichtig für komplexe Programmieraufgaben, die mehrere Schritte und Anpassungen erfordern.
Multi-Turn-Code-Generierung mit CODEGEN
Das ist beeindruckend – niemand sollte CODEGEN unterschätzen, da es auch bei der Single-Turn-Codegenerierung hervorragende Ergebnisse liefert. Dennoch haben die Forscher, die das Modell entwickelt haben, diese Untersuchungen weitergeführt und die Multi-Turn-Programmsynthese erforscht. In den meisten Programmsyntheseprozessen erhält das Modell eine vollständige Eingabeaufforderung und generiert den gesamten Code in einem Schritt.
Das Salesforce Research Team erkannte jedoch, dass ein detaillierter, schrittweiser Ansatz oft erforderlich ist, um komplexe Probleme in kleine, modulare Unteraufgaben zu zerlegen.
Um dieses Konzept zu erforschen, entwickelten die Forscher den Multi-Turn-Programming-Benchmark (MTPB). Dabei handelt es sich um einen umfassenden Datensatz mit 115 unterschiedlichen Problemstellungen, die eine Multi-Turn-Programmsynthese erfordern. Durch die Bewertung der Leistung von CODEGEN auf diesem Benchmark konnten sie die erheblichen Vorteile eines Multi-Turn-Ansatzes gegenüber einem Single-Turn-Ansatz nachweisen.
Verbesserung der Codegenerierung durch Iterative Verfeinerung
Wenn ein Nutzer ein lineares Regressionsmodell ausführen soll, kann er das Modell mit der Eingabe „Führe eine lineare Regression auf X und Y aus“ anweisen. Die Annahme ist, dass das Modell diese Anweisung korrekt versteht und sofort ein vollständiges Code-Snippet generiert. Dies kann für einfache Aufgaben nützlich sein, erweist sich jedoch bei komplexeren Programmierherausforderungen als unzureichend.
Die Multi-Turn-Programmsynthese revolutioniert diesen Prozess, indem sie Aufgaben in kleinere Schritte aufteilt, die schrittweise verbessert werden können. Beispielsweise würde das Programm bei einer linearen Regression auf X und Y nicht alles auf einmal ausführen. Stattdessen beginnt es mit dem Import der benötigten Bibliotheken und der Definition von Variablen, bevor die Aufgabe vollständig abgeschlossen wird.
Der Nutzer kann dann weitere Anweisungen geben, wie „Passe das Modell an die Daten an und gib die Koeffizienten aus“ und später „Sage die Werte für ein neues Set von X voraus und erstelle eine grafische Darstellung.“ Dies stellt sicher, dass jeder Teil der Aufgabe korrekt bearbeitet wird und auf Basis des Nutzer-Feedbacks angepasst werden kann.
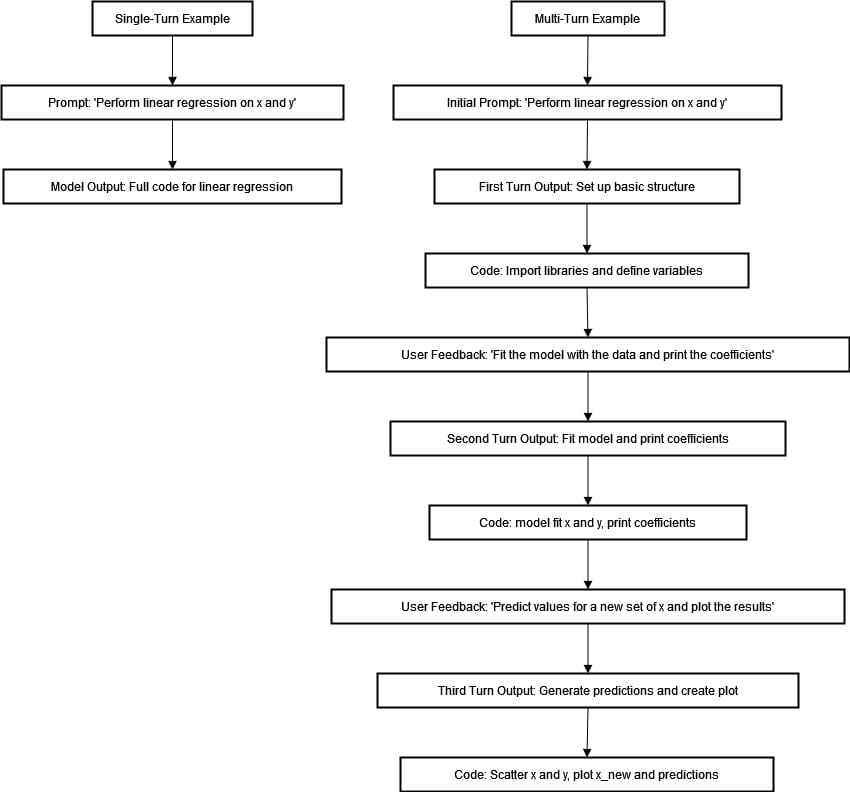
Multi-Turn-Programmsynthese: Schrittweise Ausführung
Die Nutzung mehrerer Schritte bietet viele Vorteile. Sie ermöglicht eine genauere Kontrolle über den Codeerstellungsprozess, da sich jeder Schritt auf eine bestimmte Teilaufgabe konzentriert, wodurch Fehler reduziert werden. Durch fortlaufendes Feedback des Nutzers können Anpassungen vorgenommen werden, die den Anforderungen und Vorlieben besser entsprechen.
Das obige Flussdiagramm zeigt den deutlichen Unterschied zwischen Single-Turn- und Multi-Turn-Programmsynthese bei der Erstellung eines linearen Regressionsmodells. Beim Single-Turn-Ansatz geben Nutzer die Anweisung „Führe eine lineare Regression auf X und Y aus“ und erwarten eine sofortige, vollständige Codegenerierung. Diese Methode stößt jedoch an ihre Grenzen, wenn es um komplexe Programmieraufgaben geht, die Verständnis und iterative Verfeinerung erfordern.
Im Multi-Turn-Ansatz wird der Prozess schrittweise abgeschlossen. Der Nutzer beginnt mit einer Eingabeaufforderung und erhält strukturierte Antworten, die helfen, grundlegende Rahmenbedingungen wie erforderliche Bibliotheken und Variablen einzurichten. Jede weitere Interaktion beinhaltet Feedback, das das Modell durch das Anpassen der Daten, das Drucken der Koeffizienten, die Vorhersage neuer Werte und die Erstellung von Visualisierungen leitet.
Integration von CODEGEN mit Hugging Face Transformers
Ein weiteres zentrales Element für ein Hugging Face-basiertes System ist die Transformers-Bibliothek, ein leistungsstarkes Open-Source-Toolkit, das Entwicklern den Zugriff auf LLMs wie CODEGEN ermöglicht. Durch die Integration von CODEGEN in die Transformers-Bibliothek können Nutzer das Modell einfach in ihre Anwendungen und Arbeitsabläufe einbinden.
Beispiel: Nutzung von CODEGEN mit Hugging Face Transformers
Hier ist ein Beispiel, wie Sie CODEGEN mit der Hugging Face Transformers-Bibliothek nutzen können:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-2B-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-2B-mono")
inputs = tokenizer("# this function prints hello world", return_tensors="pt")
sample = model.generate(inputs, max_length=128)
print(tokenizer.decode(sample[0], truncate_before_pattern=[r"\n\n^#", "^'''", "\n\n\n"]))
Ausgabe:
# diese Funktion gibt "Hello World" aus
def hello_world():
print("Hello World")
hello_world()
Verständnis des Codes
Der obige Code zeigt, wie das Modell CODEGEN-2B-mono geladen und zur Codegenerierung basierend auf einer Eingabe verwendet wird. Hier ist eine Übersicht der Schritte:
- Import der erforderlichen Funktionen aus der Transformers-Bibliothek.
- Laden des CODEGEN-2B-mono-Modells und des Tokenizers mithilfe der Klassen
AutoTokenizerundAutoModelForCausalLM. - Definieren der Eingabeaufforderung, in diesem Fall ein Kommentar, der eine “Hello World”-Funktion beschreibt.
- Generieren der Code-Vervollständigung mit der Funktion
model.generate(), wobei verschiedene Parameter wie die maximale Länge der Ausgabe und die Sampling-Strategie festgelegt werden. - Ausgabe des generierten Codes durch Dekodierung des Ausgabe-Tensors mit dem Tokenizer.
Das Ergebnis ist eine vollständige Python-Funktion, die “Hello World” ausgibt. Alternativ können auch andere CODEGEN-Modelle wie CODEGEN-2.0 oder CODEGEN-2.5 getestet werden, indem die Modell- und Tokenizer-Pfade entsprechend angepasst werden. Die Modelle sind auf der Hugging Face Hub verfügbar.
Praktische Anwendungen für CODEGEN
Die Vielseitigkeit von CODEGEN geht weit über akademische Benchmarks hinaus und bietet zahlreiche Anwendungsmöglichkeiten in verschiedenen Branchen und Bereichen. Hier sind einige der wichtigsten Anwendungsfälle dieses Open-Source-Sprachmodells:
Automatisierte Codegenerierung
Der offensichtlichste Anwendungsfall für CODEGEN ist die automatische Codegenerierung. Entwickler können Software viel schneller erstellen, indem sie die natürliche Sprachverarbeitung von CODEGEN nutzen. Dies spart erheblich Zeit bei der Codeerstellung und -wartung, insbesondere bei Rapid Prototyping und iterativer Entwicklung.
Intelligente Codeunterstützung
CODEGEN kann in intelligente Code-Assistenzsysteme integriert werden, die Entwicklern in Echtzeit Vorschläge zu Funktionen, Codevervollständigungen und Code-Refactoring geben. Dadurch wird die Effizienz bei der Problemlösung erheblich gesteigert.
Konversationelle Programmieroberflächen
Die Multi-Turn-Fähigkeit von CODEGEN zur Programmsynthese ermöglicht die Entwicklung konversationeller Programmieroberflächen. Nutzer können in natürlicher Sprache beschreiben, was das Programm tun soll, ohne selbst Code schreiben zu müssen. Dies kann insbesondere für nicht-technische Nutzer oder Personen mit begrenzter Programmiererfahrung hilfreich sein.
Domänenspezifische Codegenerierung
CODEGEN kann für spezifische Branchen und Domänen angepasst oder feinabgestimmt werden. Sein zugrunde liegendes Wissen und die Fähigkeit zur Routine-Generierung können beispielsweise in der Finanzbranche genutzt werden, um maßgeschneiderte Handelsalgorithmen oder Risikomanagementmodelle zu erstellen. Ebenso kann CODEGEN im Gesundheitswesen für medizinische Entscheidungshilfesysteme oder Patientenmanagement-Apps eingesetzt werden.
Bildungs- und Lernanwendungen
CODEGENs Multi-Turn-Synthese kann als interaktives Lernwerkzeug für Studierende und angehende Programmierer dienen. Durch die schrittweise Integration von Feedback in den Syntheseprozess kann CODEGEN als virtueller Tutor fungieren. Es fördert die Entwicklung von Programmierfähigkeiten, logischem Denken und Problemlösungsstrategien. Besonders in Selbstlern- oder Fernunterrichtsszenarien kann CODEGEN eine wertvolle Unterstützung bieten.
Fazit
Das Open-Source-Sprachmodell CODEGEN von Salesforce Research hebt die Programmsynthese auf ein neues Niveau. Durch die Kombination der leistungsstarken Fähigkeiten großer Sprachmodelle mit dem offenen Zugang zu diesen Technologien nutzt CODEGEN jahrelange Forschung auf diesem Gebiet. Dank der Multi-Turn-Synthese-Funktionen könnte es transformative Ansätze für Programmierung und Softwareentwicklung ermöglichen.
CODEGEN bietet vielseitige Funktionen – von der Generierung menschenähnlichen Codes auf Basis einer einzigen Eingabe bis hin zu interaktiver Code-Unterstützung. Zudem ermöglicht es konversationelle Programmierinterfaces und domänenspezifische Anwendungen.
Zweifellos können Forschende und Entwickler noch viele weitere potenzielle Anwendungsfälle in der natürlichen Sprachverarbeitung für die Codegenerierung entdecken. Während Forschung und Industrie weiterhin die Grenzen dieser Technologie ausloten, erwarten wir spannende neue Entwicklungen in diesem Bereich.
