
YOLOv11: Overview and Advancements
At the YOLO Vision 2024 event, Ultralytics announced a new member to the YOLO series called YOLOv11. This article will provide an overview of the new model, instructions on how to run inference using YOLOv11, and the key advancements and highlights of the model compared to its predecessor.
Introduction
The YOLOv11 model is designed to be fast, accurate, and easy to use for tasks such as object detection, image segmentation, image classification, pose estimation, and real-time object tracking. The new state-of-the-art (SOTA) model has achieved faster inference speed and improved accuracy compared to the previous YOLO models. Before we begin, let’s take a look at the benchmark results provided by Ultralytics.
Benchmark Results
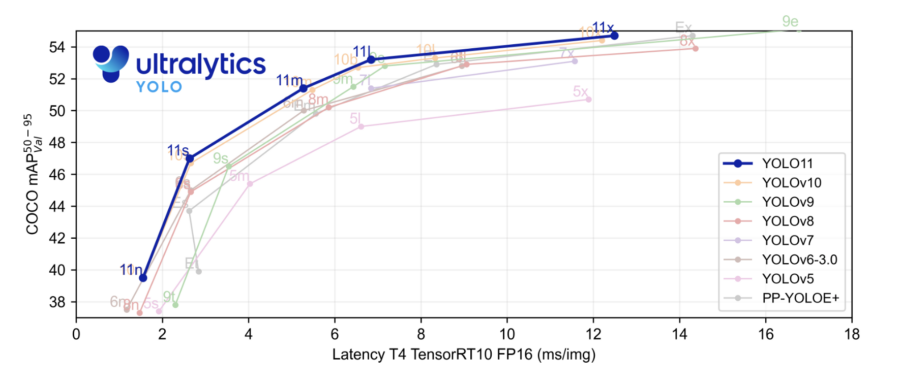
In the benchmark plot, the YOLOv11 model has been compared to YOLOv5, v6, v7, v8, v9, and v10. The highlighted blue plot is the performance of YOLOv11 and as we can see that it has surpassed pretty much all the YOLO model or the series on mean average precision on COCO dataset and on inference speed as plotted on the x-axis.
Tasks Supported by YOLOv11
- Object Detection: Locating objects in an image or videos by drawing bounding boxes along with the confidence scores. Useful for applications like autonomous driving, surveillance cameras, or traffic toll booths.
- Instance Segmentation: Identifying and segmenting objects or individuals in an image. Useful for medical imaging, manufacturing and more.
- Pose Estimation: Identifying key points in an image or video frame to monitor body movements or gestures, making it useful for applications such as virtual reality, dance training, and physical therapy.
- Oriented object detection (OBB): Detecting objects with an orientation angle, allowing more accurate localization of tilted or rotated items. This feature is particularly useful for applications such as autonomous driving, industrial inspection, and analyzing images from drones or satellites.
Model Versions
| Model | Tasks |
|---|---|
| YOLO11 | Detection (COCO) |
| YOLO11-seg | Segmentation (COCO) |
| YOLO11-pose | Pose/Keypoints (COCO) |
| YOLO11-obb | Oriented Detection (DOTAv1) |
| YOLO11-cls | Classification (ImageNet) |
YOLOv11 provides Detect, Segment, and Pose models pre-trained on the COCO dataset, as well as Classify models pre-trained on the ImageNet dataset. Track mode is also available for all Detect, Segment, and Pose models. For more information about the model details and its different versions, please refer to the official GitHub repository. We’ve included a direct link in our resources section for the convenience.
 Prerequisites
Prerequisites
Here are the prerequisites for running YOLO models:
- Python Environment: Install Python 3.8 or later.
- CUDA & cuDNN: A CUDA-compatible GPU (NVIDIA) with CUDA and cuDNN installed for faster training and inference.
- PyTorch: Install PyTorch compatible with your CUDA version.
- YOLO Framework: Install the specific YOLO version package from Ultralytics.
- Dataset: Labeled dataset in YOLO format (images and annotation files).
- Hardware Requirements: At least 16 GB RAM and a GPU with 4+ GB VRAM for smooth training and inference.
Key Feature Highlights of the New Model
YOLOv11 brings several improvements that make it a strong choice for computer vision tasks. It has a better backbone and neck design, which helps it detect objects more accurately and handle complex tasks with ease. The model is optimized for speed, offering faster processing times while still maintaining a good balance between accuracy and performance. Even with 22% fewer parameters than YOLOv8m, this lightweight model achieves higher accuracy, making it both efficient and effective. YOLOv11 also has inference time 2% quicker than the YOLOv10 thus making it highly adaptable, working well on various platforms like edge devices, cloud systems, and NVIDIA GPUs. Plus, it supports a wide range of tasks, including object detection, image classification, pose estimation, and more. YOLOv11 is designed to integrate easily with various systems and platforms. Building on YOLOv8’s support, it works well in different environments for training, testing, and deployment. Whether you use NVIDIA GPUs, edge devices, or cloud platforms, YOLOv11 fits smoothly into your workflow. These features make YOLOv11 adaptable for different industries.
YOLOv11 Demo
When YOLOv11 is run on a ccloud³ VM with Cloud GPU, the inference speed reaches up to 5 to 6 ms per image, making it an ideal choice for real-time applications that require fast and efficient processing. We will start by installing the ultralytics package or upgrading the package.
!pip install ultralytics --upgrade
Train the YOLOv11 model for object detection can be done both by either Python or using CLI commands.
from ultralytics import YOLO
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
# Train the model on the COCO8 example dataset for 100 epochs
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
# Load a COCO-pretrained YOLO11n model and train it on the COCO8 example dataset for 100 epochs
yolo train model=yolo11n.pt data=coco8.yaml epochs=100 imgsz=640
We have provided the code to use the model for detecting objects in a video.
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
results = model("data/video.mp4", save=True, show=True)
Next, we will try the model to detect objects in an image.
# Load a COCO-pretrained YOLO11n model
model = YOLO("yolo11n.pt")
results = model("/folder_path/image_det.jpeg")
results[0].show()
To use the model for segmentation, we need to download the YOLO11 as trying the model directly might throw an error.
#segmentation
from ultralytics import YOLO
model = YOLO('yolo11n-seg.pt')
results = model("/folder_path/image_seg.jpeg")
results[0].show()
Similarly, for pose estimation and classification tasks we need to download the YOLO11 model and then try the model on an image.
#pose-estimation
from ultralytics import YOLO
model = YOLO('yolo11n-pose.pt')
results = model("/folder_path/image_pose.jpeg")
results[0].show()
#image-classification
from ultralytics import YOLO
model = YOLO('yolo11n-cls.pt')
results = model("/folder_path/image_class.jpeg")
results[0].show()

Now it is advisable to use a high-end GPU to run or train YOLOv11 else training or inferencing might be slow and inefficient. When it comes to running or training YOLOv11, choosing GPU over CPU can significantly enhance performance and efficiency. YOLOv11, with its enhanced feature extraction and improved accuracy, demands high computational power, especially for training on large datasets. GPUs are specifically designed for parallel processing, enabling them to handle the complex matrix operations required for deep learning at a much faster rate than CPUs.
Concluding Thoughts
We saw some cool things the model can do with images and videos. YOLOv11 is a powerful and versatile model for computer vision tasks. Its improved features and high speed and accuracy make it a significant upgrade over its predecessors. In conclusion, YOLOv11 is a big step forward in object detection and computer vision. With its better architectural design, faster speeds, and improved accuracy, it’s an excellent fit for various uses—real-time detection on small devices or more detailed analysis in the cloud. Its ability to work smoothly with existing systems means businesses can easily integrate it into their daily operations, whether in farming, security, or robotics. YOLOv11’s blend of flexibility and performance makes it a powerful tool for anyone tackling computer vision challenges. However, this is part 1 of the tutorial, and in part 2, we will learn how to fine-tune and train the model for object detection on a custom dataset.
