
Understanding Vector Databases and Their Importance
Traditional databases’ limitations are no longer mysterious in a world fueled by high-dimensional data. Vector databases are database systems designed for storing and managing high-dimensional vectors, representing numerical representations of data that capture semantic information.
This article features some of the most popular vector databases tools, such as Pinecone, FAISS, Weaviate, Milvus, Chroma, Elastic Vector Search, Annoy, and Qdrant. We also explore their strengths, limitations, and use cases to guide the reader in the growing vector database space.
Prerequisites
To follow this tutorial, you must understand high-dimensional data, vector embeddings, and similarity searches. It requires some knowledge of Python, Rust, or TypeScript and machine learning techniques with frameworks such as PyTorch. You must know how to create a development environment using Python 3.8+ and machine learning libraries to use Pinecone, FAISS, Milvus, and Qdrant most efficiently.
Why Are Vector Databases Necessary?
Understanding High-Dimensional Data
High-dimensional data, which consists of data containing many variables, is prevalent in applications where complex features need to be computed and compared. For instance, in natural language processing (NLP), each word can be encoded as a vector, and similar words are located close to each other in vector space. These vector representations capture subtle nuances, enabling the analysis of complex relationships. Traditional databases struggle to handle this type of data due to their reliance on tabular data structures, whereas vector databases are specifically designed to manage high-dimensional data efficiently.
The Need for Efficient Similarity Search
One critical feature of vector databases is their ability to perform similarity searches. A similarity search identifies the “closest” record in the database to a given vector. This capability is crucial for applications such as recommendation engines and personalization tools. Unlike traditional keyword searches or SQL queries, similarity searches rely on advanced indexing mechanisms like Approximate Nearest Neighbors (ANN), which vector databases are optimized to support.
To illustrate this, consider a semantic search engine. When a user searches for “luxury hotels” using natural language input, a vector-based engine interprets the search and finds phrases with similar semantic meanings, such as “5-star hotels” or “touristy resorts.” This process enables the engine to retrieve more relevant results.
In contrast, traditional databases would struggle with such queries because they primarily perform exact matches or use rigid SQL models. They lack the flexibility to understand and process the nuanced relationships present in vector spaces.
A semantic search engine encodes the user query into a vector, performs a similarity search across other vectors, and returns semantically related results like “5-star hotels” and “touristy resorts.” Meanwhile, a traditional database handling the same query using exact matching would fail to provide relevant results. This stark difference highlights the limitations of traditional databases in processing semantic relationships.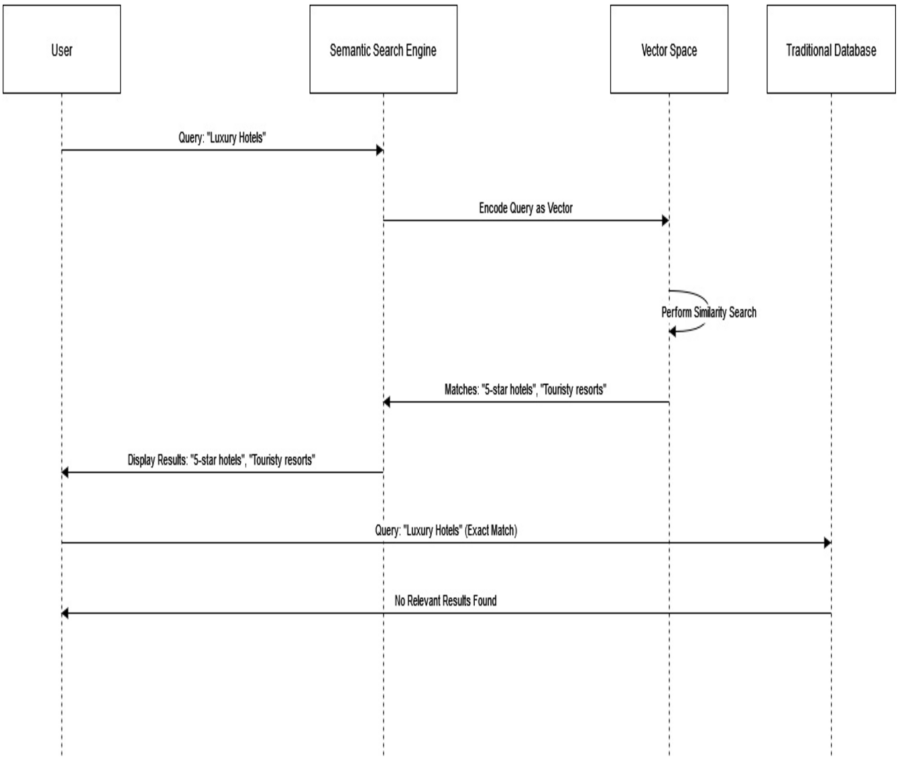
AI and Machine Learning Integration
Vector databases are naturally suited for artificial intelligence (AI) and machine learning (ML) applications. AI models frequently generate vectors to represent the data they process. For seamless integration with real-time applications, databases must efficiently store, retrieve, and index these vectors.
Consider an image recognition system as an example. When a user uploads an image of a landmark, the AI model processes the image and generates a vector embedding that captures its contours, colors, and textures. This vector is then stored in a vector database.
If the user uploads another similar image later, the system can search the database for the most similar vector embeddings and accurately identify the landmark. The efficiency of storing, accessing, and indexing vectors in the database is essential for enabling real-time recognition and similarity matching.
Current Options in the Vector Database Landscape
As vector databases rise in popularity, several solutions have emerged, each with unique strengths and limitations. We will examine some of the top vector databases available today.
Introduction to Pinecone
Pinecone is a powerful vector database built to support the needs of modern AI and machine learning projects. As a fully managed service, it reduces the time it takes to store, index, and query large amounts of vector data. Consequently, Pinecone is ideal for real-time similarity searches and large-scale applications. Its simplicity and performance have made Pinecone one of the pioneers in the growing vector database space.
How Pinecone Works
Pinecone allows developers to store, index, and query high-dimensional data as vectors. This is helpful in recommendation systems or semantic search engines, where it is important to understand the similarity between products.
Step-1: Install and Import Pinecone
pip install pinecone-client
We must also import the necessary modules into the Python code:
from pinecone import Pinecone, ServerlessSpec
Step-2: Initialize Pinecone
pc = Pinecone(api_key="API_KEY")
Step-3: Create an Index
index_name = "index_use_case"
pc.create_index(name=index_name,
dimension=6,
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
Step-4: Connect to the Index
index = pc.Index("index_use_case")
Step-5: Insert Data into the Index
data = [
{"id": "items1", "values": [1, 2, 3, 4, 5, 6]},
{"id": "items2", "values": [8, 7, 6, 5, 4, 3]},
]
index.upsert(items=data)
Step-6: Query the Index
query_v = [2, 1, 4, 3, 6, 5]
res = index.query(vector=query_v, top_k=3)
Step-7: Manage Your Index
print(pc.list_indexes())
pc.delete_index("index_use_case")
Strengths of Pinecone
- Ease of Use: Pinecone’s fully managed approach allows developers to implement it into their applications with minimum effort. The API-first structure makes it accessible even for those unfamiliar with vector databases.
- High Performance: Pinecone’s emphasis on speed allows even the most complex similarity searches with large data sets to be executed in milliseconds.
- Reliable Scalability: Pinecone scales up without compromising performance as data grows, making it ideal for start-ups and enterprise-level deployments.
- Cross-Platform Integration: It supports an efficient model-to-production process and is compatible with multiple AI frameworks.
Weaknesses of Pinecone
- Limited Flexibility: Pinecone’s managed architecture can feel too locked down for some developers, as it does not allow for the same customization and control as self-hosted solutions.
- Dependency on Cloud: Pinecone is a cloud service that may not be suitable for enterprises with a high on-premise data use case.
FAISS Explained: Optimizing Similarity Search and Clustering for Large-Scale Data
FAISS stands for Facebook AI Similarity Search, an open-source library that can perform similarity search and clustering of dense vectors. Dense vectors are numerical representations of data (e.g., text embeddings, images, audio tracks) in machine learning models.
FAISS is optimized to:
- Find the nearest neighbors of a query vector among millions or even billions of other vectors.
- Provide fast and memory-efficient performance using product quantization and inverted file indexing methods.
- Scale efficiently on both CPUs and GPUs, enabling real-time and large-scale offline deployment.
How FAISS Works
Indexing
FAISS creates an index of vectors using various indexing techniques to optimize similarity searches:
- Flat Index: Organizes vectors for exhaustive search. It is highly accurate but computationally intensive for large datasets.
- IVF (Inverted File): Partitions vectors into clusters and restricts the search space to clusters relevant to queries.
- Product Quantization (PQ): Reduces vectors into smaller representations, sacrificing some accuracy for faster searches and lower memory usage.
- HNSW (Hierarchical Navigable Small World): Builds a graph where nodes represent vectors, enabling rapid traversal to find nearest neighbors.
Search Query
FAISS searches indexed vectors when a query vector is provided using exact or approximate methods:
- Exact Searches: Compare the query vector to all vectors in the index, ensuring maximum accuracy.
- Approximate Searches: Use techniques like compressed representations or clustering to accelerate search while maintaining reasonable accuracy.
Distance Metrics
FAISS offers different similarity metrics for various use cases:
- Euclidean Distance: Measures the straight-line distance between vectors.
- Cosine Similarity: Evaluates similarity based on the angle between vectors.
Getting Started with FAISS
Installation
To install FAISS, run the following command:
pip install faiss-cpu
For GPU support:
pip install faiss-gpu
Basic Usage Example
Here’s a simple example of how to implement FAISS for nearest neighbor search:
import numpy as np
import faiss
dim = 64 # Dimension of vectors
b = 10000 # Number of database vectors
q = 1000 # Number of query vectors
np.random.seed(234)
x_b = np.random.random((b, dim)).astype('float32') # Database vectors
x_q = np.random.random((q, dim)).astype('float32') # Query vectors
index = faiss.IndexFlatL2(dim) # L2 distance index
index.add(x_b) # Add database vectors
k = 3 # Number of nearest neighbors to retrieve
D, I = index.search(x_q, k) # Search for nearest neighbors
print(I[:3]) # Print top 3 results
Strengths of FAISS
- Speed: FAISS enables rapid similarity searches, even for datasets with billions of vectors. GPU support enhances performance.
- Scalability: Its design scales efficiently for massive datasets, supporting large-scale applications.
- Flexibility: FAISS offers a range of indexing options to meet different performance and accuracy needs.
- Open Source: FAISS benefits from community support and is freely available for customization.
Challenges and Limitations of FAISS
- Complexity: Requires a solid understanding of indexing methods and trade-offs, which may challenge beginners.
- Accuracy vs. Speed: Approximate searches may sacrifice accuracy for speed, unsuitable for applications demanding high precision.
- Memory Usage: Exact searches on large datasets can require significant memory resources.
- Learning Curve: Proper implementation can be time-consuming and requires technical expertise.
Weaviate: An Open-Source Vector Database
Weaviate is a cutting-edge tool for storing raw data and its semantic representations. Unlike traditional databases, which work using an organized SQL-like pattern, Weaviate uses AI-driven vector embeddings for similarity-based queries. This feature is necessary for context-driven applications like conversational AI, recommendation engines, content categorization, and more.
How Weaviate Enables Semantic Understanding
Weaviate transforms a search query like “biology” into a semantic vector representation and compares it to stored vectors for contextual matches. This approach allows the system to return the most relevant documents, even if they don’t contain the exact keyword “biology.”
The process works as follows:
- Search: A user inputs a query, for example, “biology.” In traditional databases, this would trigger a basic keyword search.
- Convert Query to Vector: Weaviate vectorizes the query using models like OpenAI or Sentence Transformers, capturing its semantic meaning.
- Find Similar Vectors: The query vector is compared with stored data vectors using distance metrics like cosine similarity.
- Return Top Matches: Weaviate ranks and returns the most relevant matches based on semantic similarity scores.
Strengths of Weaviate
- Semantic Search: Unlike keyword-based engines, Weaviate understands the context of queries and returns more relevant results.
- Modular Vectorization: Weaviate supports multiple vectorization models, making it adaptable to various data types.
- High Performance: Uses HNSW indexing for rapid query execution, even with millions of data points.
- User-Friendly APIs: GraphQL and REST APIs make Weaviate accessible for both developers and non-technical users.
Challenges and Limitations of Weaviate
- Model Dependency: The accuracy of search results depends heavily on the performance of the chosen vectorization model.
- High Computational Demand: Vectorization and data storage can require significant computational resources.
- Complex Setup: Initial configuration may be challenging for users unfamiliar with vector databases.
- Limited for Traditional Queries: Weaviate is less effective for SQL-like operations common in relational databases.
Milvus: Setting Up Milvus Lite for Local Vector Database Management
Milvus is an open-source vector database that efficiently organizes and searches vector data at scale. It’s particularly useful for knowledge bases, semantic search, and retrieval-augmented generation (RAG) applications. We’ll explore how to install and use Milvus Lite for local deployments.
Installing Milvus Lite
pip install -U pymilvus
Creating a Collection in Milvus
from pymilvus import MilvusClient
client = MilvusClient("milvus_demo.db")
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection",
dimension=768,
)
Inserting Data into Milvus
We will create vector embeddings and insert them into the collection:
from pymilvus import model
embedding_fn = model.DefaultEmbeddingFunction()
documents = [
"Artificial intelligence is a field in computer science.",
"There are many computer scientists today.",
"Deep learning is a subset of artificial intelligence."
]
vectors = embedding_fn.encode_documents(documents)
dataset = [
{"id": i, "vector": vectors[i], "text": documents[i], "subject": "history"}
for i in range(len(vectors))
]
res = client.insert(collection_name="demo_collection", data=dataset)
print(res)
Querying the Milvus Database
query_vectors = embedding_fn.encode_queries(["What is Deep Learning?"])
res = client.search(
collection_name="demo_collection",
data=query_vectors,
limit=2,
output_fields=["text", "subject"]
)
print(res)
Strengths of Milvus
- High Performance: Designed for fast similarity searches, even with billions of vectors.
- Scalability: Supports large datasets without compromising performance.
- Community Support: Active developer community and robust documentation.
Challenges and Limitations of Milvus
- Operational Complexity: Requires technical expertise to set up and scale effectively.
- Resource Intensive: High infrastructure demands for large-scale deployments.
Chroma Vector Database
Chroma is a lightweight and intuitive vector database designed for ease of use and fast deployment. It is particularly well-suited for small applications and prototyping projects where simplicity and rapid integration are essential.
Strengths of Chroma
- Easy Setup: Chroma can be installed and configured quickly without extensive training or technical expertise.
- Lightweight Design: Its minimal system requirements make it ideal for environments with limited infrastructure.
- Real-Time Updates: Chroma allows for dynamic data retrieval and real-time embedding updates, essential for applications like recommendation engines and chatbots.
- API Integration: Chroma’s user-friendly API supports seamless integration with various programming languages and machine learning frameworks.
Challenges and Limitations of Chroma
- Limited Scalability: Chroma may struggle with handling very large datasets compared to more robust vector databases.
- Lack of Advanced Features: It lacks some advanced functionalities offered by more mature vector database solutions.
Elastic Vector Search: Strengths, Weaknesses, and Applications
Elastic Vector Search extends the capabilities of Elasticsearch to support similarity searches across large sets of vector data. This makes it highly effective for use cases such as recommendation engines, personalization tools, and hybrid search solutions.
Strengths of Elastic Vector Search
- Scalability: Offers horizontal scaling and a distributed design to handle massive datasets.
- Hybrid Search: Supports combined keyword and vector-based searches for enhanced query flexibility.
- Integration with Elastic Stack: Seamlessly integrates with tools like Kibana for data visualization and Logstash for data ingestion.
- Customizable Schemas: Allows flexible schema definitions and supports various indexing methods, such as HNSW.
Challenges and Limitations of Elastic Vector Search
- High Resource Consumption: Requires significant memory and CPU resources for large-scale operations.
- Complex Configuration: Setup and optimization may require deep knowledge of Elasticsearch and vector data management.
- Trade-Offs: Approximate nearest neighbor searches may sacrifice accuracy for speed.
Annoy (Approximate Nearest Neighbors Oh Yeah)
Annoy is an open-source library developed by Spotify for fast approximate nearest neighbor searches in high-dimensional spaces. It is optimized for use cases like recommendation systems and search engines where quick, approximate results are acceptable.
Strengths of Annoy
- Fast Approximate Search: Uses tree-based indexing for efficient nearest neighbor searches.
- Memory Efficiency: Employs memory-mapped files to handle large datasets without loading everything into memory.
- Simple API: Offers an easy-to-use interface for integration into applications.
Challenges and Limitations of Annoy
- Single-Threaded Indexing: Index creation is limited to a single thread, slowing down performance on large datasets.
- Approximation Trade-Offs: Sacrifices some accuracy for speed, which may not be suitable for all use cases.
- Lack of Database Features: Focuses solely on vector search without offering broader database functionalities.
Qdrant: Open-Source Vector Database for Fast and Accurate Similarity Search
The open-source vector database Qdrant is designed for fast and accurate similarity search in high-dimensional data, making it well-suited for machine learning and AI applications.
Qdrant Architecture
Qdrant organizes data into collections, where each collection holds:
- Vectors: High-dimensional data representations.
- Payloads: Metadata providing additional context or characteristics for each vector.
 Similarity Search in Qdrant
Similarity Search in Qdrant
Qdrant is designed to perform similarity searches using advanced distance metrics:
- Euclidean Distance: Measures the straight-line distance between vectors.
- Cosine Similarity: Compares vectors based on the angle between them.
- Dot Product: Measures vector similarity through projection.
Strengths of Qdrant
- High Performance: Delivers fast and accurate nearest neighbor searches using HNSW indexing.
- Real-Time Updates: Supports dynamic data updates for real-time applications.
- Flexible Querying: Offers filtering and metadata management for complex queries.
Challenges and Limitations of Qdrant
- Complex Setup: Requires technical expertise for deployment and optimization.
- Infrastructure Requirements: Large-scale deployments demand significant infrastructure resources.
Conclusion
Vector databases have revolutionized high-dimensional data management by addressing the limitations of traditional databases. They enable applications like recommendation systems, semantic search, and AI-driven solutions.
From Pinecone, FAISS, Weaviate, Milvus, Chroma, Elastic Vector Search, Annoy, to Qdrant, each database offers unique strengths for specific use cases. However, their limitations—such as cost, setup complexity, and trade-offs between speed and accuracy—must be carefully evaluated before implementation.
Choosing the right vector database depends on application requirements, infrastructure, and resource availability. Careful consideration ensures optimal integration and performance for scalable, high-performing applications.
