
AI and Deep Learning: The Power of Voice Cloning
One of the coolest possibilities offered by AI and Deep Learning technologies is the ability to replicate various things in the real world. Whether it be generating realistic images from scratch or the right response to an incoming chat request or appropriate music for a given theme, we can rely on AI to deliver awesome approximations of the things previously only possible when guided directly by a human’s hand.
Voice Cloning: A Revolutionary Technology
Voice cloning is one of those interesting possibilities offered by this novel tech. This is the quality of mimicking the voice qualities of some actor by attempting to recreate their specific intonation, accent, and pitch using some deep learning model. When combined with technologies like Generative Pretrained Transformers and static image manipulators, like SadTalker, we can start to make some really interesting approximations of real life human behaviors – albeit from behind a screen and speaker.
Steps to Clone Your Own Voice Using Tortoise TTS
In this short article, we will walk through each of the steps required to clone your own voice, and then generate accurate impersonations of yourself using Tortoise TTS. We can then take these clips and combine them with other projects to create some really interesting outcomes with AI.
Tortoise TTS
Released by solo author James Betker, Tortoise is undoubtedly the best and easiest to use voice cloning model available for use on local and cloud machines without requiring any sort of API or service payment to access. It makes it easy to clone a voice from just a few (3-5) 10 second voice clips.
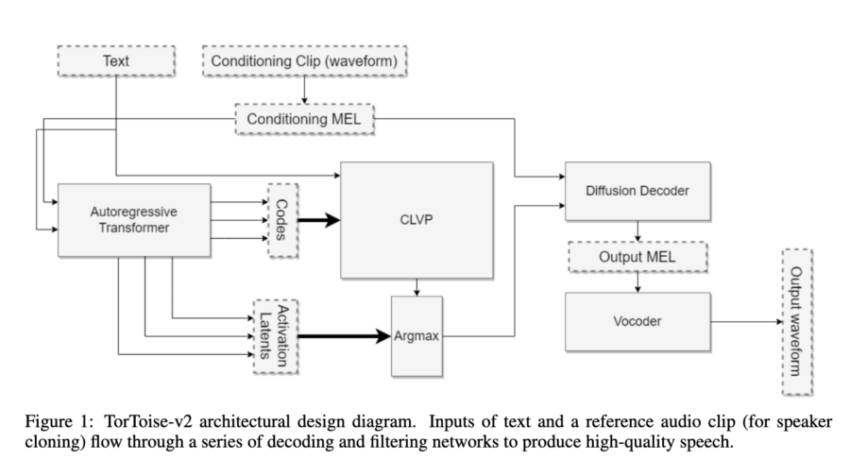
How Tortoise TTS Works
In terms of how it works and its inspiration, both lie with image generation with AutoRegressive Transformers and Denoising Diffusion Probabilistic Models. The author sought to recreate the success of those model approaches, but applied towards speech generation. In those models, they learn the process of image generation with a step-wise probabilistic procedure which, over time and large amounts of data, learn the image distribution.
With TorToise, the model is specifically trained on visualizations of speech data called MEL spectrograms. These representations of the audio can be easily modeled using the same process as used in typical DDPM situations with only slight modification to account for voice data. Additionally, we add the ability to mimic some existing voice type by using it as an initial noise object weight condition.
Together, this can be used to accurately recreate voice data using very little initial input.
Demo: Running Tortoise TTS
To get started with Tortoise TTS, open the Notebook environment, locate the tortoise_tts.ipynb file, and run the first cell. This will set up the necessary dependencies and initialize the model.
Selecting Voice Samples
Choosing the right voice samples is crucial for achieving high-quality voice cloning. Below are some tips to ensure the best results:
- Use a high-quality microphone: If you don’t have a professional microphone, a mobile phone often provides better noise reduction than a standard laptop microphone.
- Record in a quiet, echo-free environment: A closet full of clothing can help dampen any unwanted reverberations.
- Prepare a script: Reading from a script minimizes unnecessary pauses, “um” sounds, and stutters.
- Include diverse phonemes: Using phonetic pangrams like “That quick beige fox jumped in the air over each thin dog” helps the AI capture a broad range of speech sounds.
Following these suggestions, along with the original recommendations, will ensure a smoother cloning process. Below are the voice samples we used for this demonstration:
Ethical Considerations
Cloning voices raises ethical and legal concerns. You should never use someone’s voice without their explicit permission. We strongly discourage any malicious or deceptive use of voice cloning technology. It should only be used for parody, research, or personal projects.
Code Breakdown
Before we begin, we need to set up the workspace. The first step involves installing the required dependencies. Unfortunately, not all dependencies are listed in the original requirements.txt file, so we need to install some additional packages manually.
# First, follow the instructions in the README.md file under Local Installation
!pip3 install -r requirements.txt
!pip install librosa einops rotary_embedding_torch omegaconf pydub inflect
!python3 setup.py install
The next step involves importing the necessary modules and downloading the pre-trained model:
# Imports used through the rest of the notebook.
import torch
import torchaudio
import torch.nn as nn
import torch.nn.functional as F
import IPython
from tortoise.api import TextToSpeech
from tortoise.utils.audio import load_audio, load_voice, load_voices
# This will download all the models used by Tortoise from the HF hub.
# tts = TextToSpeech()
# If you want to use deepspeed the pass use_deepspeed=True nearly 2x faster than normal
tts = TextToSpeech(use_deepspeed=True, kv_cache=True)
Once the model is downloaded, we can generate speech using a default voice:
# This is the text that will be spoken.
text = "Joining two modalities results in a surprising increase in generalization! What would happen if we combined them all?"
# Here's something for the poetically inclined.. (set text=)
"""
Then took the other, as just as fair,
And having perhaps the better claim,
Because it was grassy and wanted wear;
Though as for that the passing there
Had worn them really about the same,"""
# Pick a "preset mode" to determine quality. Options: {"ultra_fast", "fast" (default), "standard", "high_quality"}. See docs in api.py
preset = "ultra_fast"
Uploading Your Own Voice Recordings
We can now upload our own voice recordings to the directory /notebooks/tortoise-tts/tortoise/voices. Use the file navigator on the left side of the GUI to find this folder, and create a new subdirectory named voice_test. Upload your sample recordings to this folder.
Once the upload is complete, we can run the next cell to see all available voices that we can use for the demo.
# Tortoise will attempt to mimic voices you provide.
# It comes pre-packaged with some voices you might recognize.
# Let's list all the available voices.
# These are some random clips I've gathered from the internet
# as well as a few voices from the training dataset.
# Feel free to add your own clips to the voices/ folder.
%ls tortoise/voices
# Play a sample voice
IPython.display.Audio('tortoise/voices/tom/1.wav')
List of Available Voices
After running the above code, you should see a list of available voices similar to this:
angie/ freeman/ myself/ tom/ train_grace/ applejack/ geralt/ pat/ train_atkins/ train_kennard/ cond_latent_example/ halle/ pat2/ train_daws/ train_lescault/ daniel/ jlaw/ rainbow/ train_dotrice/ train_mouse/ deniro/ lj/ snakes/ train_dreams/ weaver/ emma/ mol/ tim_reynolds/ train_empire/ william/
Starting Voice Cloning
Now we are finally ready to begin voice cloning. Use the code in the following cell to generate a sample clone using the text variable as input. Note that we can adjust the speed (fast, ultra_fast, standard, or high_quality), which can have a significant effect on the final output.
# Pick one of the voices from the output above
voice = 'voice_test'
# Define the text to be spoken
text = 'Hello, you have reached the voicemail of myname. Please leave a message.'
# Load the voice samples and conditioning latents
voice_samples, conditioning_latents = load_voice(voice)
# Generate the cloned speech using Tortoise
gen = tts.tts_with_preset(text, voice_samples=voice_samples, conditioning_latents=conditioning_latents,
preset=preset)
# Save and play the generated audio file
torchaudio.save('generated.wav', gen.squeeze(0).cpu(), 24000)
IPython.display.Audio('generated.wav')
Modify Text and Re-run
Change the text variable in the code cell above and run it again to generate different speech outputs using your cloned voice!
Closing Thoughts
Voice cloning with Tortoise TTS opens up a world of possibilities. Whether for entertainment, research, or personal projects, the ability to synthesize human-like speech from a few samples is an incredible feat of modern AI. Experiment with different inputs, tweak the settings, and explore the full potential of neural voice cloning.
